При разработке любого программного продукта перед командой разработчиков прежде всего стоит задача грамотного выбора программной платформы, определяющей структуру программной системы.
Для этого нужно учесть достаточно большое количество характеристик, от «как быстро всё будет работать» до «а необходима ли нам эта фича?». И так каждый раз. Именно в моменты мозгового штурма команда сравнивает удобство фреймворка, скорость, набор фич, которые реализованы в нем или в совместимых с ним модулях.
Но какой же всё-таки лучше, быстрее и производительнее?
Разработчики постоянно проводят сравнение фреймворков, чтобы прояснить для себя этот вопрос. Например, в статье Lukasz Kujawa приведено сравнение PHP фреймворков. Одно «но» — статья за 2013 год. А ведь время идёт… Поэтому мы решили провести своё, актуальное сравнение фреймворков.
Для оценки производительности был использован PHP Framework Benchmark. Он предлагает для сравнения множество фреймворков (не только указанных выше), но автор не спешит добавлять в репозиторий новые версии проектов, что, конечно же, печально, хотя и не смертельно. При желании добавить новую версию не сложно.
Одной из основных целей данной статьи также является попытка практическим путем определить улучшения в производительности и эффективности новых версий PHP. Поэтому тестирование было проведено на РНР 5.6/7.0/7.1
Что будем сравнивать?
Для сравнения были выбраны следующие фреймворки:
- slim-3.0
- ci-3.0
- lumen-5.1
- yii-2.0
- silex-1.3
- fuel-1.8
- phpixie-3.2
- zf-2.5
- zf-3.0
- symfony-2.7
- symfony-3.0
- laravel-5.3
- laravel-5.4
- bluz (версия 7.0.0 — для РНР5.6 и версия 7.4 для РНР7.0 и выше)
- ze-1.0
- phalcon-3.0
Тестирование условно разделено на 4 вида:
- производительность (throughput),
- занимаемая память (memory),
- время выполнения (exec time),
- количество подключаемых файлов (included files).
Методика тестирования и тестовый стенд
Машина, на которой производилось тестирование, обладает следующими характеристиками:
Operation system: Linux Mint 17 Cinnamon 64-bit
Cinnamin Version 2.2.16
Linux Kernel: 3.13.0-24-generic
Processor: Intel Core i3-4160 CPU 3.60 Ghz X 2
Memory: 8 GB
Server version: Apache/2.4.7 (ubuntu)
Server build: Jul 15 2016
php 7.1 / php7.0 / php5.6
Вводим команду git clone https://github.com/kenjis/php-framework-benchmark — и фрейм уже на нашей машине. Поскольку мы использовали Mint, необходимо выполнить настройку:
# Added
net.netfilter.nf_conntrack_max = 100000
net.nf_conntrack_max = 100000
net.ipv4.tcp_max_tw_buckets = 180000
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_fin_timeout = 10
sudo sysctl -p
Немного о структуре самого php-framework-benchmark:
/benchmarks — содержит bash-скрипты, отвечающие за сбор информации о количестве запросов в секунду (при помощи утилиты ab), количестве информации, сколько времени было потрачено и сколько файлов вызывалось из файла «точки старта».
/lib — директория, в которой находятся файлы, отвечающие за обработку полученной информации после вывода страницы “Hello world”, вывод таблиц с результатами и построение диаграмм.
/output — директория, в которую добавляются логи после выполнения тестирования. Здесь находится по два файла для каждого протестированного файла: .ab.log — лог после работы утилиты ab, и .output — содержит информацию, которая была выведена на экран (обычно это hello world и данные по памяти, времени выполнения, использовавшимся файлам).
Остальные папки — это заготовки фреймов, в которые уже добавлен один контроллер, который вернет строку “hello world” при обращении по URI, составленному по правилам обращения к данному фреймворку.
Для запуска теста сначала нужно настроить фреймворки. Рассмотрим два подхода.
Команда bash setup.sh настроит те фремворки, которые описаны в файле list.sh. Вы можете его редактировать: добавлять и удалять папки для тестирования. То есть конфигурировать так, как вам необходимо.
Командой bash setup.sh fatfree-3.5/ slim-3.0/ lumen-5.1/ silex-1.3/ вы можете установить какие-то отдельные фреймворки, задав их параметрами к команде. В некоторых случаях это удобно, но мы использовали первый подход.
После произведенной настройки фреймворков, мы запустили тестирование при помощи bash benchmark.sh.
По окончании работы в терминале появилась таблица со списком протестированных фреймворков, количеством запросов в секунду, относительным значением, занимаемой памятью, а также относительными значениями этих показателей.
Для отображения графиков мы воспользовались ссылкой http://localhost/php-framework-benchmark/.
Как вы понимаете, необходимо было произвести настройку Apache и заставить его смотреть в папку с фреймом. Всё это описано в readme, поэтому вопросов не возникает.
Результаты тестирования фреймворков
Каждый раздел имеет структуру, состоящую из двух форм представления результатов.
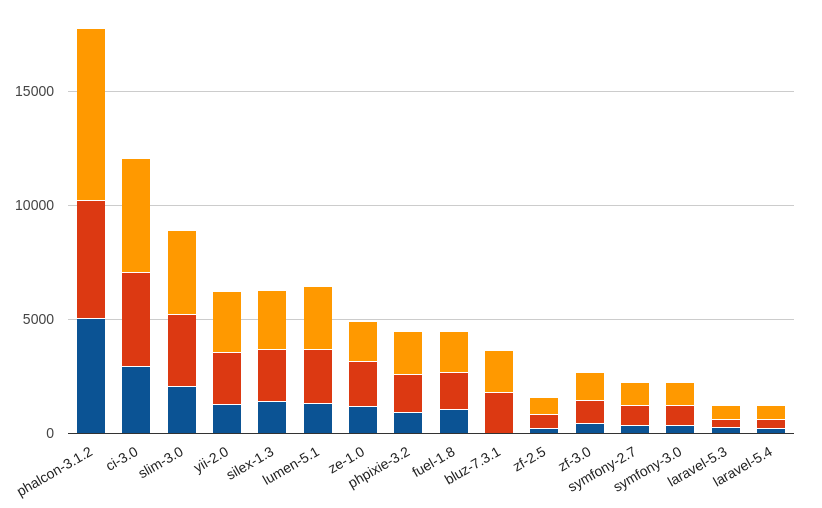
Первая форма — это наглядный тип представления. Каждая характеристика содержит 4 диаграммы. Каждая диаграмма отображает сравнение фреймворков между собой, плюс накопительная диаграмма. Она была построена при использовании определенной версии РНР. Таким образом можно проследить эволюцию улучшений в PHP и фреймворках.
Вторая форма — это результат тестирования в виде таблицы (хватить наглядности, давайте говорить серьезно — дайте мне больше чисел!).
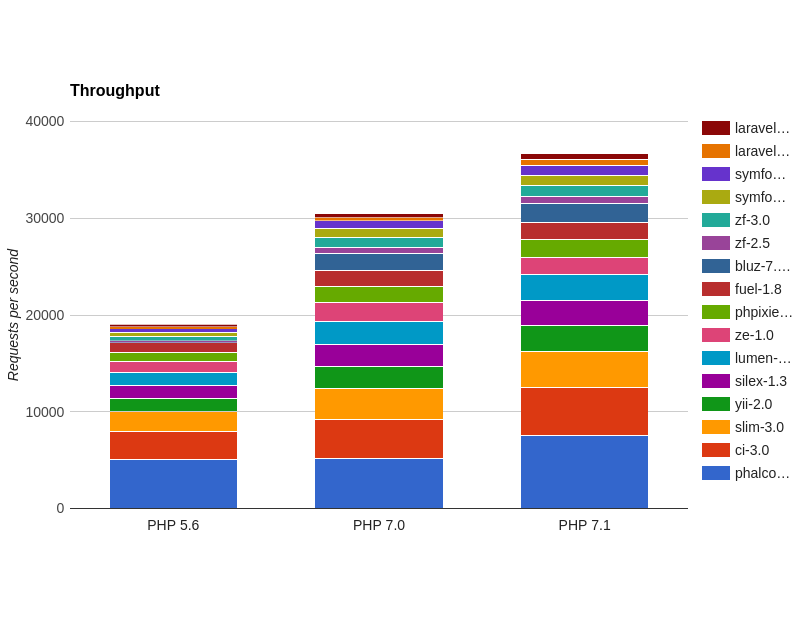
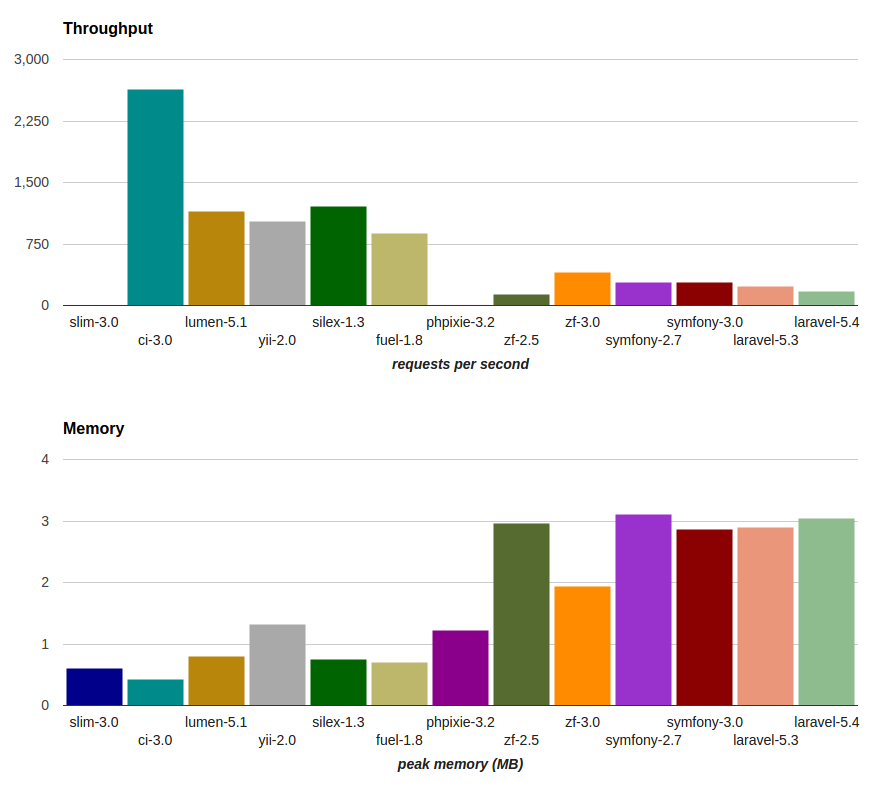
Производительность (throughput)
Применительно к нашей ситуации, характеристика throughput измеряется в количестве запросов, которые наш фреймворк может обработать в течении секунды. Следовательно, чем выше это число, тем более производительно наше приложение, поскольку оно сможет корректно обрабатывать запросы большого количества пользователей.
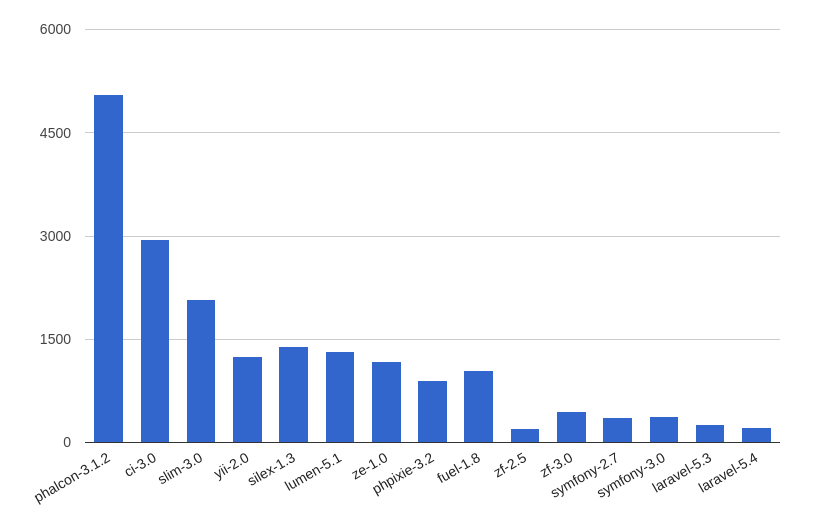
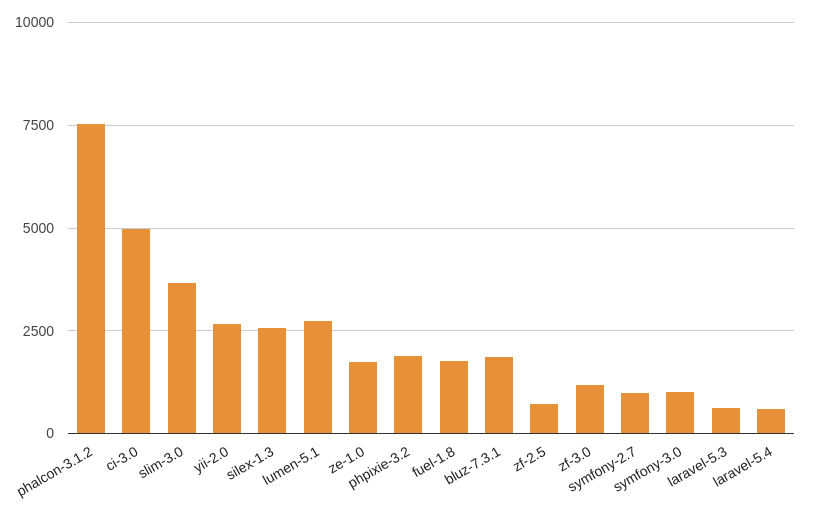
Мы получили следующие результаты (запросы в секунду):
|
php 5.6 |
php 7.0 |
php 7.1 |
| phalcon-3.1.2 |
5058.00 |
5130.00 |
7535.00 |
| ci-3.0 |
2943.55 |
4116.31 |
4998.05 |
| slim-3.0 |
2074.59 |
3143.94 |
3681.00 |
| yii-2.0 |
1256.31 |
2276.37 |
2664.61 |
| silex-1.3 |
1401.92 |
2263.90 |
2576.22 |
| lumen-5.1 |
1316.46 |
2384.24 |
2741.81 |
| ze-1.0 |
1181.14 |
1989.99 |
1741.81 |
| phpixie-3.2 |
898.63 |
1677.15 |
1896.23 |
| fuel-1.8 |
1044.77 |
1646.67 |
1770.13 |
| bluz-7.3.1 |
— * |
1774.00 |
1890.00 |
| zf-2.5 |
198.66 |
623.71 |
739.12 |
| zf-3.0 |
447.88 |
1012.57 |
1197.26 |
| symfony-2.7 |
360.03 |
873.40 |
989.57 |
| symfony-3.0 |
372.19 |
853.51 |
1022.28 |
| laravel-5.3 |
258.62 |
346.25 |
625.99 |
| laravel-5.4 |
219.82 |
413.49 |
600.42 |
* — bluz-7.3.1 не поддерживает php 5.6
Для наглядности построили графики для каждой версии PHP:
PHP5.6:
PHP7.0:
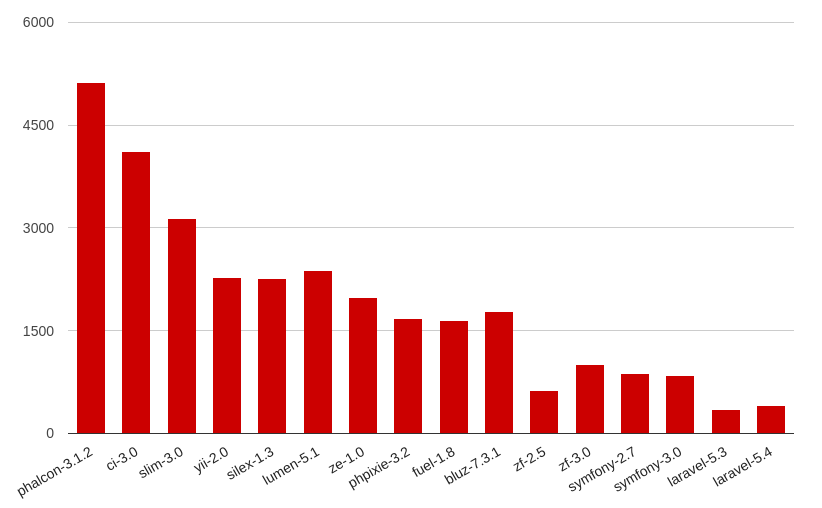
PHP7.1:
Сводная накопительная диаграмма (по фреймворкам):
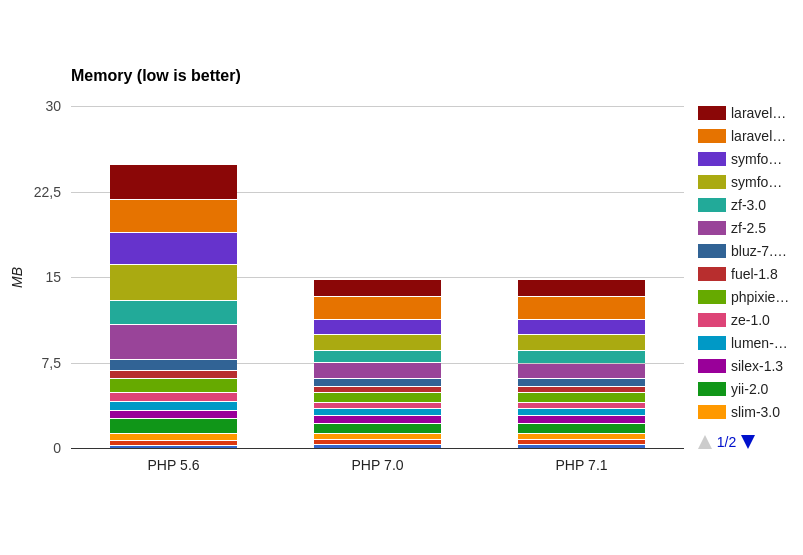
Занимаемая память (peak memory)
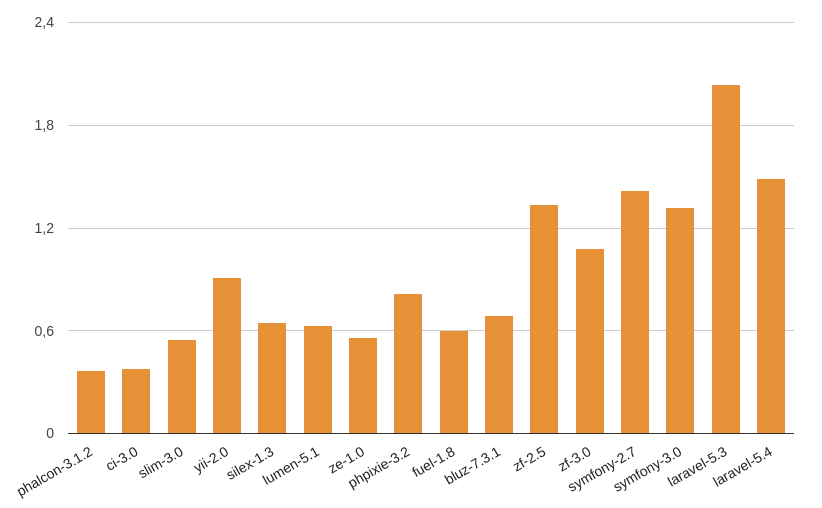
Эта характеристика (в мегабайтах) отвечает за количество занимаемой фреймворком памяти при выполнении поставленной перед ним задачи. Чем меньше данное число, тем лучше для нас и для сервера:
|
php 5.6 |
php 7.0 |
php 7.1 |
| phalcon-3.1.2 |
0.27 |
0.38 |
0.37 |
| ci-3.0 |
0.42 |
0.38 |
0.38 |
| slim-3.0 |
0.61 |
0.55 |
0.55 |
| yii-2.0 |
1.31 |
0.91 |
0.91 |
| silex-1.3 |
0.74 |
0.65 |
0.65 |
| lumen-5.1 |
0.80 |
0.63 |
0.63 |
| ze-1.0 |
0.79 |
0.56 |
0.56 |
| phpixie-3.2 |
1.22 |
0.82 |
0.82 |
| fuel-1.8 |
0.7 |
0.6 |
0.6 |
| bluz-7.3.1 |
— * |
0.69 |
0.69 |
| zf-2.5 |
3.06 |
1.34 |
1.34 |
| zf-3.0 |
2.12 |
1.09 |
1.08 |
| symfony-2.7 |
3.11 |
1.41 |
1.42 |
| symfony-3.0 |
2.86 |
1.30 |
1.32 |
| laravel-5.3 |
2.91 |
2.04 |
2.04 |
| laravel-5.4 |
3.04 |
1.45 |
1.49 |
* — bluz-7.3.1 не поддерживает php 5.6
PHP 5.6:
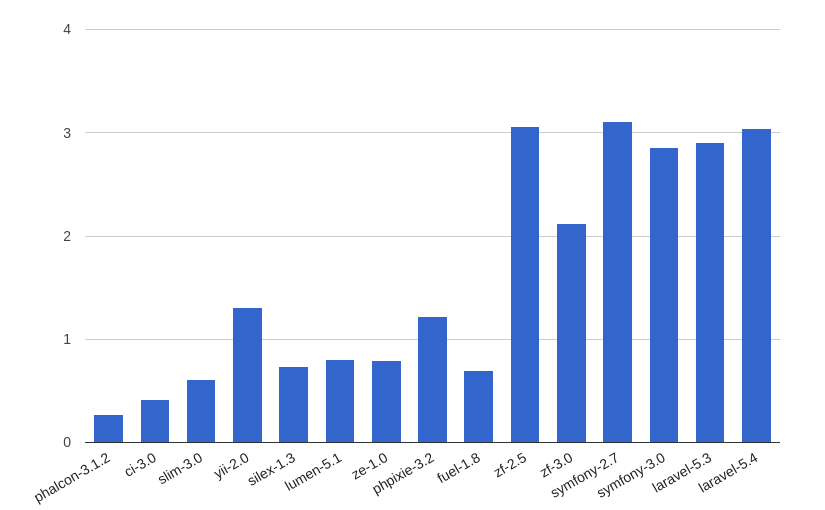
PHP 7.0:
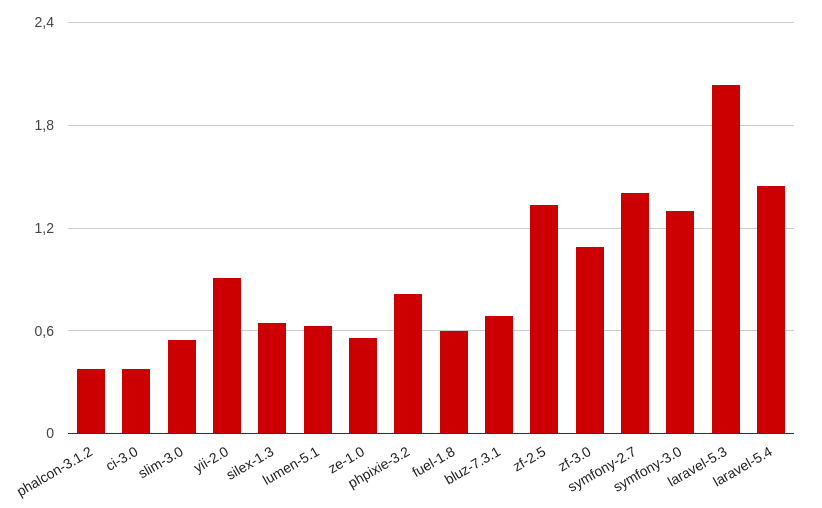
PHP 7.1:
Сводная накопительная диаграмма (по фреймворкам):
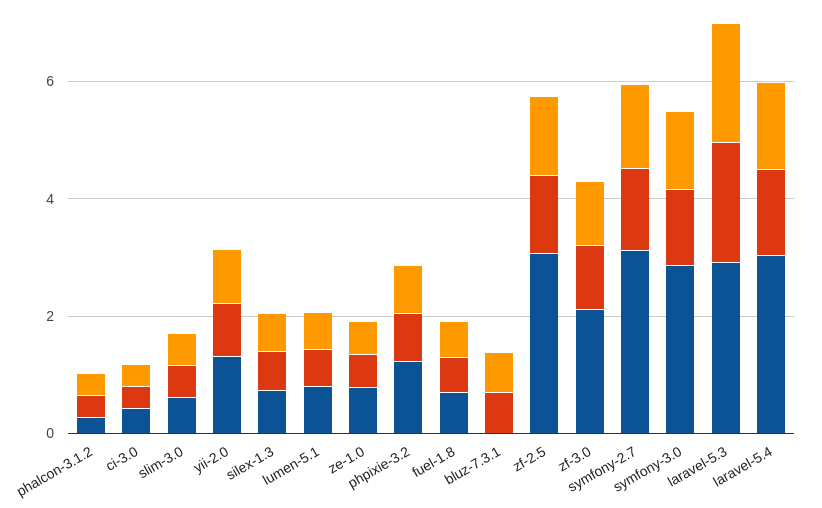
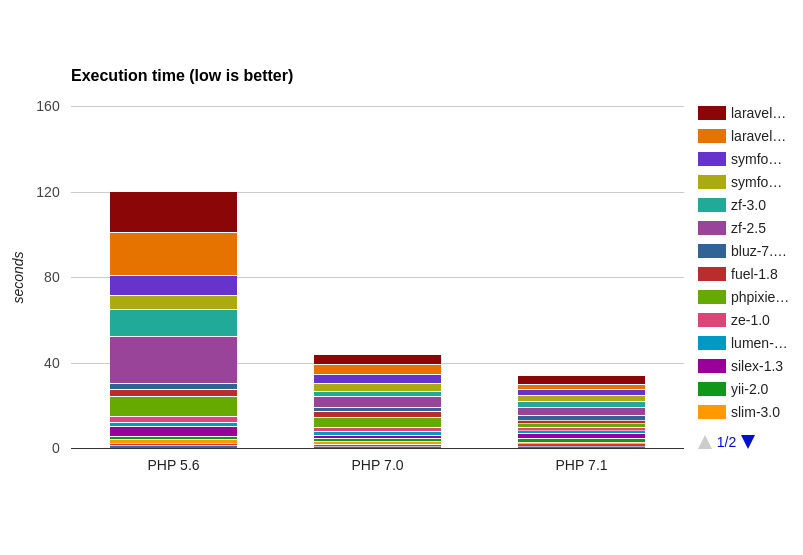
Время выполнения
Время выполнения — время, затрачиваемое системой для выполнения поставленной задачи. Измеряется от начала выполнения задачи до выдачи результата системой.
Мы рассмотрели, сколько запросов в секунду может обработать фреймворк, сколько памяти он при этом занимает. Теперь рассмотрим, сколько нам нужно ожидать, чтобы получить ответ от сервера. Чем ниже это значение, тем лучше для нас, да и для нервной системы клиента нашего приложения.
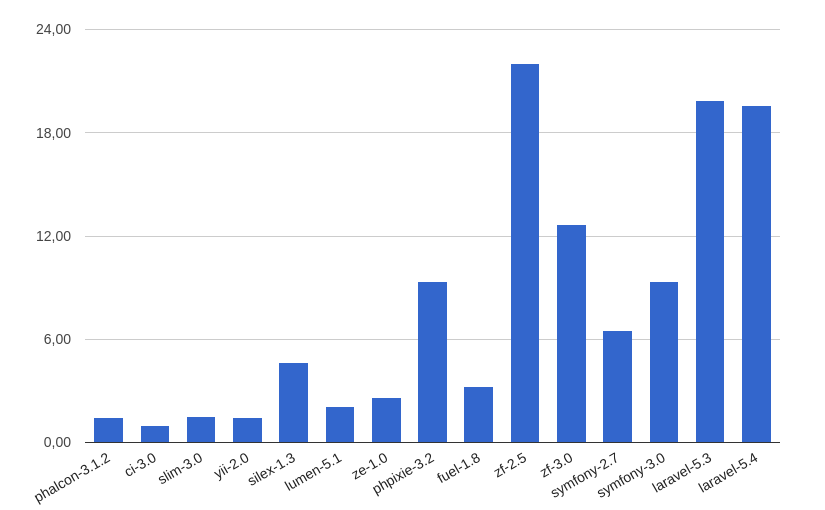
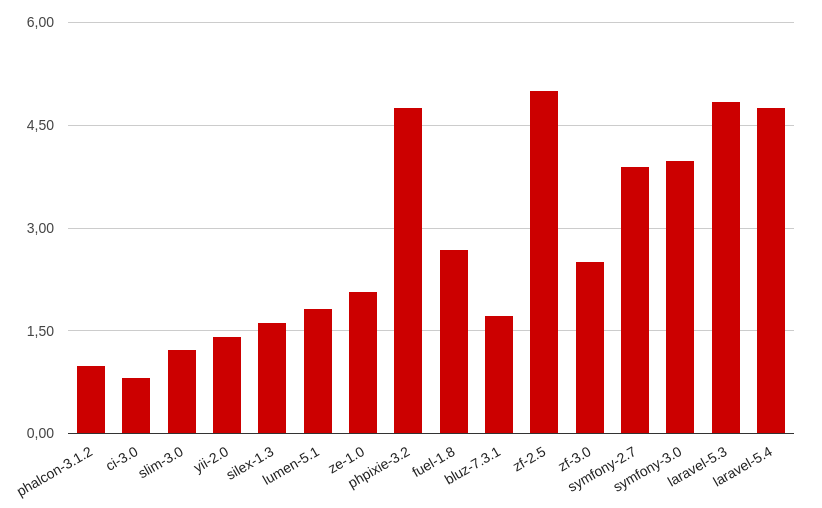
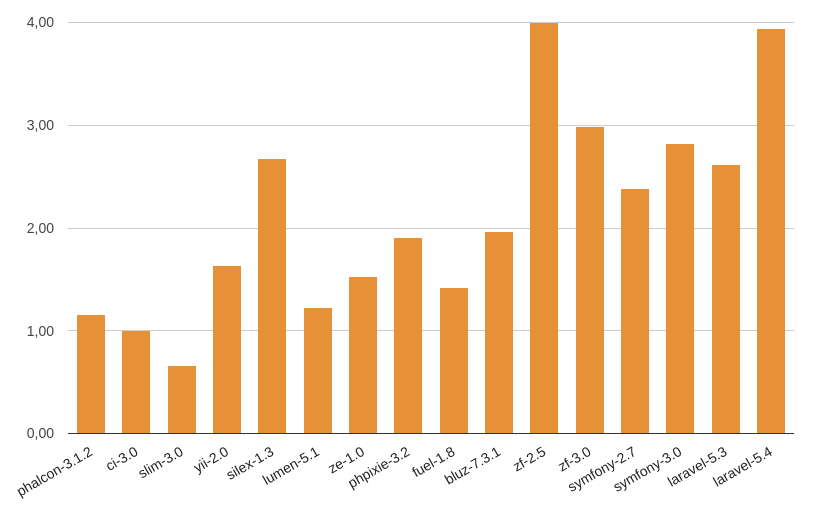
Время приведено в миллисекундах (ms):
|
php 5.6 |
php 7.0 |
php 7.1 |
| phalcon-3.1.2 |
1.300 |
1.470 |
1.080 |
| ci-3.0 |
0.996 |
0.818 |
1.007 |
| slim-3.0 |
1.530 |
1.228 |
0.662 |
| yii-2.0 |
1.478 |
1.410 |
1.639 |
| silex-1.3 |
4.657 |
1.625 |
2.681 |
| lumen-5.1 |
2.121 |
1.829 |
1.228 |
| ze-1.0 |
2.629 |
2.069 |
1.528 |
| phpixie-3.2 |
9.329 |
4.757 |
1.911 |
| fuel-1.8 |
3.283 |
2.684 |
1.425 |
| bluz-7.3.1 |
— * |
1.619 |
1.921 |
| zf-2.5 |
22.042 |
5.011 |
3.998 |
| zf-3.0 |
12.680 |
2.506 |
2.989 |
| symfony-2.7 |
6.529 |
3.902 |
2.384 |
| symfony-3.0 |
9.335 |
3.987 |
2.820 |
| laravel-5.3 |
19.885 |
4.840 |
2.622 |
| laravel-5.4 |
19.561 |
4.758 |
3.940 |
PHP 5.6:
PHP 7.0:
PHP 7.1:
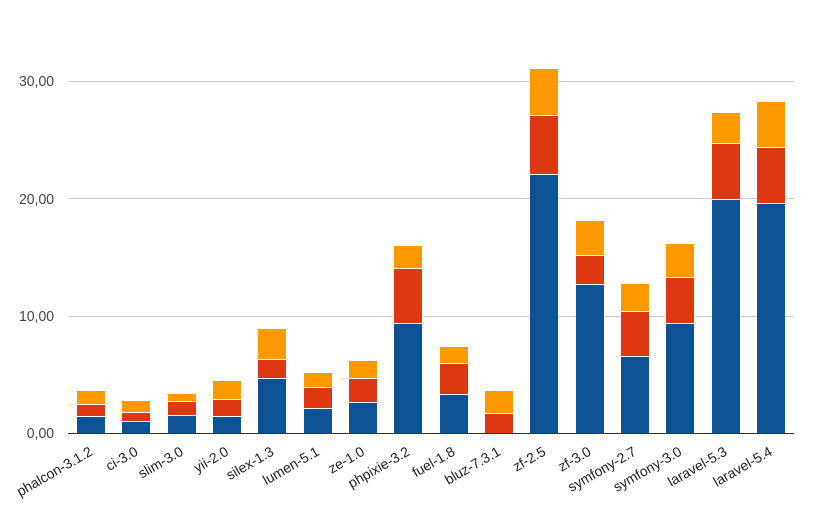
Сводная накопительная диаграмма (по фреймворкам):
Подключаемые файлы
Характеристика, отвечающая за количество подключаемых файлов, которые описаны в файле «точки входа» фреймворка. Понятно, что система тратит какое-то время на поиск и подключение. Следовательно, чем меньше файлов, тем быстрее будет осуществляться первый запуск приложения, так как обычно в последующие разы фреймворк работает с кэшем, что ускоряет работу:
| phalcon-3.1.2 |
5 |
| ci-3.0 |
26 |
| slim-3.0 |
53 |
| yii-2.0 |
46 |
| silex-1.3 |
63 |
| lumen-5.1 |
37 |
| ze-1.0 |
68 |
| phpixie-3.2 |
163 |
| fuel-1.8 |
53 |
| bluz-7.3.1 |
95 |
| zf-2.5 |
222 |
| zf-3.0 |
188 |
| symfony-2.7 |
110 |
| symfony-3.0 |
192 |
| laravel-5.3 |
38 |
| laravel-5.4 |
176 |
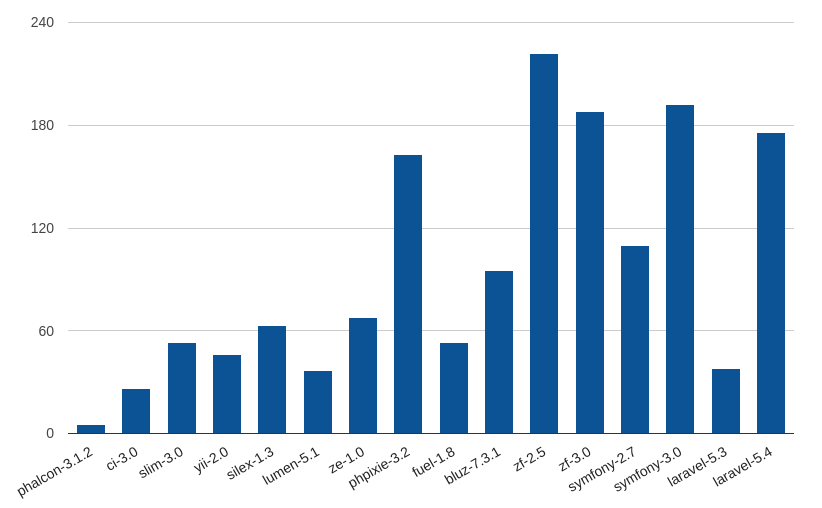
Разница в количестве подключаемых файлов между Laravel 5.3 и Laravel 5.4 может показаться странной и дать повод к обсуждениям, спорам и т.п. Спешим разъяснить ситуацию. Как вы знаете, с помощью команды
php artisan optimize --force
в Laravel 5.3 можно сгенерировать файл compiled.php, и тем самым уменьшить количество подключаемых файлов, собрав их в один. Но есть одно «но»: команды для генерации этого файла в Laravel 5.4 больше нет. Разработчик решил удалить эту фичу, так как посчитал (https://github.com/laravel/framework/pull/17003), что для настройки производительности лучше использовать opcache.
Стоит ли обновляться?
Сводные данные по версиям более чем наглядно показывают, какой произойдет прирост производительности и эффективности использования ресурсов при переходе (или изначальном выборе) на новую версию PHP.
При переходе с PHP 5.6 на PHP 7.0 средний прирост производительности составил почти +90%, при этом минимальный прирост производительности составил +33% для Laravel 5.3, а максимум — >200% для Zend Framework 2.5.
Переход с версии 7.0 на 7.1 уже не так шокирует, но всё же в среднем даёт почти 20% прирост производительности.
Сведя все полученные данные по производительности различных версий PHP, получим вот такие «матрасы»:
Забавный факт: Laravel 5.3 показал наименьший прирост производительности при миграции с PHP 5.6 на PHP 7.0, но при этом наибольший прирост при миграции с версии 7.0 на версию 7.1, и как итог — производительность Laravel 5.3 и 5.4 на PHP 7.1 практически одинакова.
Потребление памяти тоже оптимизировали, так что переход с PHP 5.6 на PHP 7.0 позволит вашему приложению потреблять на 30% меньшем памяти.
Обновление с версии 7.0 до версии 7.1 практически не даёт прироста, а в последних Symfony и Laravel так и вовсе уходим в «минус», потому что они начинают чуть больше «кушать».
Осталось ещё посмотреть на время выполнения, и да, тут тоже всё отлично:
- переезд с PHP 5.6 на PHP 7.0 подарит вам ускорение в среднем на 44%.
- переезд с PHP 7.0 на PHP 7.1 подарит вам ускорение ещё на 14%.
Примечание. Тестирование при помощи ab — с чем мы столкнулись
«А что со slim и phpixie» — этот вопрос подтолкнул на расследование поведения утилиты ab при взаимодействии с этими фреймворками.
Выполним тест отдельно для Slim-3.0:
ab -c 10 -t 3 http://localhost/php-framework-benchmark/slim-3.0/index.php/hello/index
Concurrency Level: 10
Time taken for tests: 5.005 seconds
Complete requests: 2
Failed requests: 0
Total transferred: 1800 bytes
HTML transferred: 330 bytes
Requests per second: 0.40 [#/sec] (mean)
Time per request: 25024.485 [ms] (mean)
Time per request: 2502.448 [ms] (mean, across all concurrent requests)
Transfer rate: 0.35 [Kbytes/sec] received
Что-то не так — количество запросов в секунду всего 0.4 (!)
ab -c 10 -t 3 http://localhost/php-framework-benchmark/laravel-5.4/public/index.php/hello/index
Concurrency Level: 10
Time taken for tests: 3.004 seconds
Complete requests: 1961
Failed requests: 0
Total transferred: 1995682 bytes
HTML transferred: 66708 bytes
Requests per second: 652.86 [#/sec] (mean)
Time per request: 15.317 [ms] (mean)
Time per request: 1.532 [ms] (mean, across all concurrent requests)
Transfer rate: 648.83 [Kbytes/sec] received
Дело было в Keep Alive соединении, подробнее можно узнать тут.
“When you make requests with «Connection: keep-alive» the subsequent request to the server will use the same TCP connection. This is called HTTP persistent connection. This helps in reduction CPU load on server side and improves latency/response time.
If a request is made with «Connection: close» this indicates that once the request has been made the server needs to close the connection. And so for each request a new TCP connection will be established.
By default HTTP 1.1 client/server uses keep-alive where as HTTP 1.0 client/server don’t support keep-alive by default.”
Таким образом, тест для Slim должен выглядеть так:
ab -H 'Connection: close' -c 10 -t 3 http://localhost/php-framework-benchmark/slim-3.0/index.php/hello/index
Concurrency Level: 10
Time taken for tests: 3.000 seconds
Complete requests: 10709
Failed requests: 0
Total transferred: 2131091 bytes
HTML transferred: 353397 bytes
Requests per second: 3569.53 [#/sec] (mean)
Time per request: 2.801 [ms] (mean)
Time per request: 0.280 [ms] (mean, across all concurrent requests)
Transfer rate: 693.69 [Kbytes/sec] received
Заключение
Как и стоило ожидать безоговорочным лидером по производительности (но не скорости разработки) является Phalcon. Второе место, — а на самом деле первое среди PHP-фреймворков (а не C, на котором написан исходный код Phalcon) — занимает CodeIgniter 3!
Конечно же, не стоит забывать, что каждому инструменту своё предназначение. Если вы выбираете небольшой и легкий фреймворк и собираетесь написать на нём что-то отличное от простейших приложений или REST API, то, скорее всего, вы столкнётесь с проблемами при расширении функционала. И наоборот — избыточность полнофункциональных, больших фреймворков повлечёт за собой финансовые издержки на содержание хостинга даже для элементарных приложений под большой нагрузкой.
Это тестирование проводилось для того, чтобы убедить/рассказать/укрепить позицию языка РНР версий 7.0 и 7.1 в вашем сознании и в будущих проектах, донести информацию о том, что производительность действительно возросла.
Рефакторинг внутренних структур данных и добавление дополнительного этапа перед компиляцией кода в виде абстрактного синтаксического дерева — Abstract Syntax Tree (AST), — привели к превосходной производительности и более эффективному распределению памяти. Результаты сами по себе выглядят многообещающе: тесты, выполненные на реальных приложениях, показывают, что PHP 7 в среднем вдвое быстрее PHP 5.6, а также использует на 50% меньше памяти во время обработки запросов, что делает PHP 7 сильным соперником для компилятора HHVM JIT от Facebook.
Тесты полностью подтверждают и вдвое ускорившуюся обработку запроса в РНР7, и уменьшенное количество используемой памяти.
Оригинал: Как выбрать тот самый PHP-фреймворк. Сравнительное тестирование









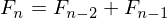 Эта последовательность обладает одним замечательным свойством, а именно:
Эта последовательность обладает одним замечательным свойством, а именно: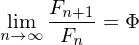 Число Фи, представляет собой золотую пропорцию, которая часто встречается в природе, выражая собой закон гармонии и красоты…
Число Фи, представляет собой золотую пропорцию, которая часто встречается в природе, выражая собой закон гармонии и красоты…