
Не все знают, что Python не задумывался создателями как язык для анализа данных. Однако сегодня это один из самых лучших языков для статистики, машинного обучения, прогнозной аналитики, а также стандартных задач по обработке данных. Python — язык с открытым кодом, и специалисты по data scienceએ стали создавать инструменты, чтобы более эффективно выполнять свои задачи. Сайт DEV.BY со ссылкой на ресурс Data36 опубликовал пять сторонних библиотек и пакетов, не встроенных в Python 3, которые должен знать каждый аналитик.
NumPy
NumPy позволяет очень эффективно обрабатывать многомерные массивы. Многие другие библиотеки построены на NumPy, и без неё было бы невозможно использовать pandas, Matplotlibએ, SciPyએ или scikit‑learnએ — именно поэтому она занимает первое место в списке.
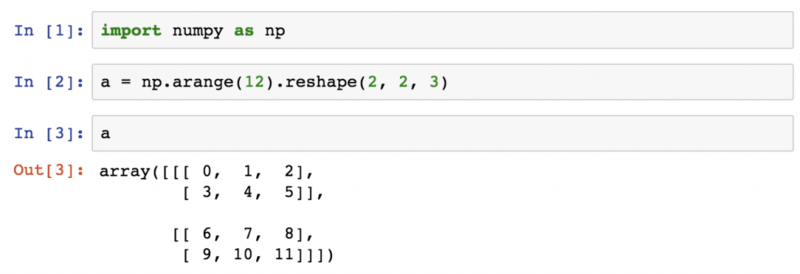 >
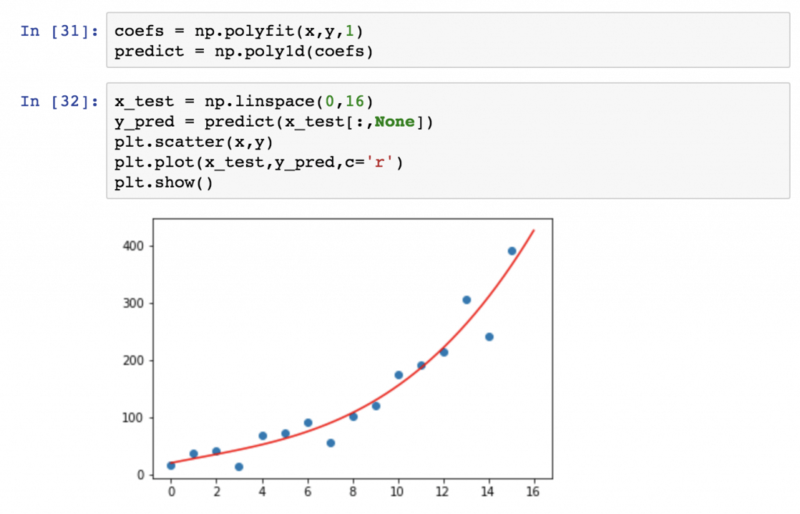
>Также в ней есть несколько хорошо реализованных методов, например, функция random, которая гораздо качественнее модуля случайных чисел из стандартной библиотеки. Функция polyfit отлично подходит для простых задач по прогнозной аналитике, например, по линейной или полиномиальной регрессии.
 >
>pandas
Аналитики данных обычно используют плоские таблицы, такие, как в SQL и Excel. Изначально в Python такой возможности не было. Библиотека pandas позволяет работать с двухмерными таблицами на Python.
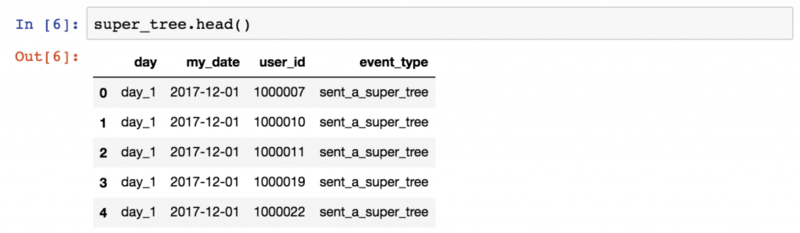
Эта высокоуровневая библиотека позволяет строить сводные таблицы, выделять колонки, использовать фильтры по параметрам, выполнять группировку по параметрам, запускать функции (сложение, нахождение медианы, среднего, минимального, максимального значений), объединять таблицы и многое другое. В pandas можно создавать и многомерные таблицы.
Matplotlib
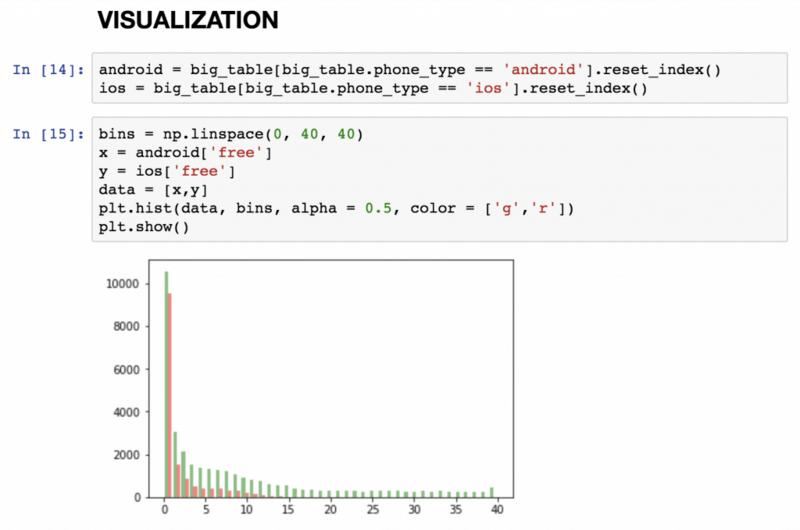
Визуализация данных позволяет представить их в наглядном виде, изучить более подробно, чем это можно сделать в обычном формате, и доступно изложить другим людям. Matplotlib — лучшая и самая популярная Python-библиотека для этой цели. Она не так проста в использовании, но с помощью 4-5 наиболее распространённых блоков кода для простых линейных диаграмм и точечных графиков можно научиться создавать их очень быстро.
scikit‑learn
Самыми интересными возможностями Python некоторые считают машинное обучение и прогнозную аналитику, а наиболее подходящая для этого библиотека — scikit‑learn. Она содержит ряд методов, охватывающих всё, что может понадобиться в течение первых нескольких лет в карьере аналитика данных: алгоритмы классификации и регрессии, кластеризацию, валидацию и выбор моделей. Также её можно применять для уменьшения размерности данных и выделения признаков.
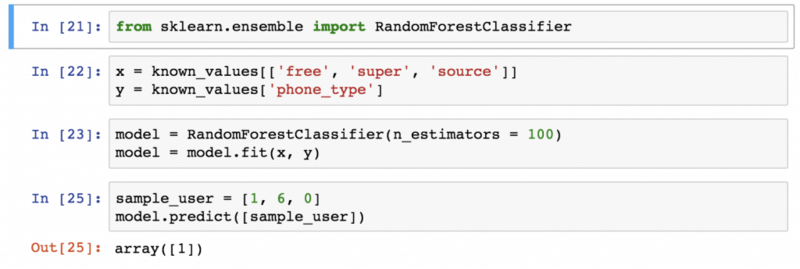
Машинное обучение в scikit‑learn заключается в том, чтобы импортировать правильные модули и запустить метод подбора модели. Сложнее вычистить, отформатировать и подготовить данные, а также подобрать оптимальные входные значения и модели. Поэтому прежде чем взяться за scikit‑learn, нужно, во-первых, отработать навыки работы с Python и pandas, чтобы научиться качественно подготавливать данные, а во-вторых, освоить теорию и математическую основу различных моделей прогнозирования и классификации, чтобы понимать, что происходит с данными при их применении.
SciPy
Существует библиотека SciPy и стек SciPy. Большинство описанных в этой статье библиотек и пакетов входят в стек SciPy, предназначенный для научных расчётов на Python. Библиотека SciPy — один из его компонентов, который включает средства для обработки числовых последовательностей, лежащих в основе моделей машинного обучения: интеграции, экстраполяции, оптимизации и других.
Как и в случае с NumPy, чаще всего используется не сама SciPy, а упомянутая выше библиотека scikit‑learn, которая во многом опирается на неё. SciPy полезно знать потому, что она содержит ключевые математические методы для выполнения сложных процессов машинного обучения в scikit‑learn.
Другие библиотеки и пакеты для обработки и анализа данных
Есть также множество библиотек и пакетов на Python для обработки изображений и естественного языка, глубокого обучения, нейронных сетей и так далее. Однако поначалу лучше освоить пять основных библиотек, и лишь после этого браться за более узконаправленные.
Как начать пользоваться библиотеками pandas, NumPy, Matplotlib, scikit‑learn и SciPy
В первую очередь нужно настроить сервер базы данных. Далее нужно дополнительно установить все инструменты:
- Подключиться к серверу
- Установить NumPy, используя команду
- Установить pandas, используя команду
sudo apt-get install python3-pandas - Обновить дополнительные инструменты pandas с помощью двух команд:
sudo -H pip3 install —upgrade beautifulsoup4и
sudo -H pip3 install —upgrade html5lib - Установить scikit‑learn, используя команду
sudo -H pip3 install scikit‑learn
После завершения установки, необходимо импортировать библиотеки (или их отдельные модули) в свои скрипты, используя корректные операторы импорта, например:
import numpy as np
import pandas as pd
import matplotlib
matplotlib.use(‘Agg’)
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.linear_model import LinearRegression
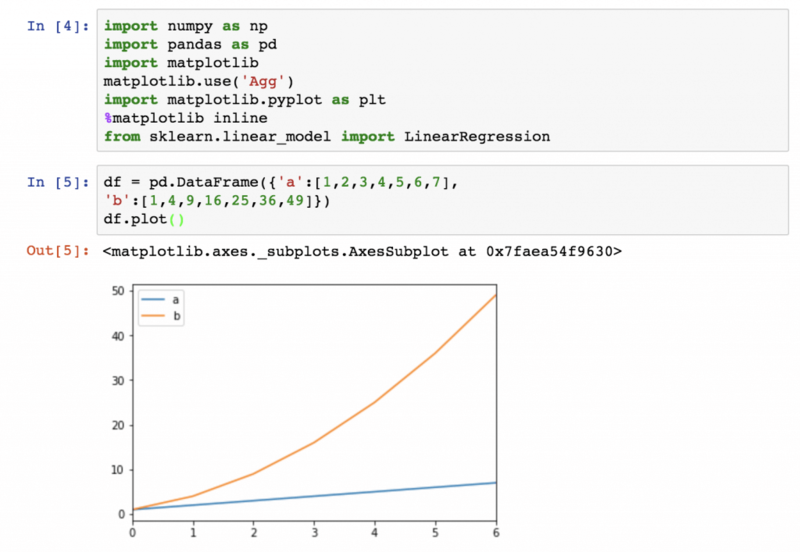
После этого можно протестировать pandas и Matplotlib вместе, запустив вот эти строки:
df = pd.DataFrame({‘a’:[1,2,3,4,5,6,7],
‘b’:[1,4,9,16,25,36,49]})
df.plot()
Использованы материалы: dev.by