Содержание
- Логистическая регрессия в Python
- Пакеты Python для логистической регрессии
- Логистическая регрессия в Python с помощью scikit‑learn: пример 1
- Логистическая регрессия в Python с помощью scikit‑learn: пример 2
- Логистическая регрессия в Python с помощью StatsModels: пример
- Логистическая регрессия в Python: распознавание рукописного ввода
- За пределами логистической регрессии в Python
- Заключение
По мере того, как объем доступных данных, вычислительные мощности и количество улучшений алгоритмов продолжают расти, растет и важность науки о данных и машинного обучения. Классификация — одна из наиболее важных областей машинного обучения, а логистическая регрессия — один из ее основных методов. К концу этого урока вы узнаете о классификации в целом и основах логистической регрессии в частности, а также о том, как реализовать логистическую регрессию в Python.
В этом уроке вы узнаете:
- Что такое логистическая регрессия.
- Для чего используется логистическая регрессия.
- Как работает логистическая регрессия.
- Как реализовать логистическую регрессию в Python, шаг за шагом.
Классификация
Классификацияએ — очень важная область машинного обучения с учителем. В эту область входит большое количество важных проблем машинного обучения. Существует множество методов классификации, и логистическая регрессия — один из них.
Что такое классификация?
Алгоритмы контролируемого машинного обучения определяют модели, которые фиксируют взаимосвязи между данными. Классификация — это область машинного обучения с учителем, которая пытается предсказать, к какому классу или категории принадлежит тот или иной объект, на основе его характеристик.
Например, вы можете проанализировать сотрудников какой-либо компании и попытаться установить зависимость от характеристик или переменных, таких как уровень образования, количество лет на текущей должности, возраст, зарплата, шансы на продвижение по службе и т.д. Набор данных, относящихся к одному сотруднику — одно наблюдение. Характеристики или переменные могут принимать одну из двух форм:
- Независимые переменные, также называемые входными данными или предикторами, не зависят от других интересующих характеристик (или, по крайней мере, вы предполагаете это для целей анализа).
- Зависимые переменные, также называемые выходами или откликами, зависят от независимых переменных.
В приведенном выше примере, когда вы анализируете сотрудников, вы можете предположить, что уровень образования, время в текущем положении и возраст как независимые друг от друга и рассматривать их как входные данные. Заработная плата и шансы на продвижение по службе могут быть результатами, которые зависят от вложений.
Примечание. Алгоритмы машинного обучения с учителем анализируют ряд наблюдений и пытаются математически выразить зависимость между входами и выходами. Эти математические представления зависимостей являются моделями.
Природа зависимых переменных различает проблемы регрессии и классификации. Задачи регрессии имеют непрерывные и обычно неограниченные результаты. Например, вы оцениваете зарплату как функцию от опыта и уровня образования. С другой стороны, задачи классификации имеют дискретные и конечные выходы, называемые классами или категориями. Например, прогнозирование того, будет ли сотрудник повышаться по службе или нет (правда или ложь), является проблемой классификации.
Есть два основных типа проблем классификации:
- Двоичная или биномиальная классификация: на выбор ровно два класса (обычно 0 и 1, истина и ложь, или положительный и отрицательный)
- Мультиклассовая или полиномиальная классификация: три или более классов выходных данных на выбор
Если имеется только одна входная переменная, она обычно обозначается как x. Для более чем одного входа вы обычно будете видеть векторную запись x = (x_1,\dots, x_r), где r — количество предикторов (или независимых признаков). Выходная переменная часто обозначается символом и принимает значения 0 или 1.
Когда вам нужна классификация?
Вы можете применять классификацию во многих областях науки и техники. Например, алгоритмы классификации текста используются для разделения легитимных писем и спама, а также положительных и отрицательных комментариев. Вы можете ознакомиться с Practical Text Classification With Python and Keras, чтобы получить некоторое представление об этой теме. Другие примеры включают медицинские приложения, биологическую классификацию, кредитный рейтинг и многое другое.
Задачи распознавания изображений часто представляют как задачи классификации. Например, вы можете спросить, имеется ли на изображение человеческое лицо или нет, мышь или слон, какую цифру от нуля до девяти оно представляет и т.д. Чтобы узнать больше об этом, ознакомьтесь с материалами Traditional Face Detection With Python и Face Recognition with Python, in Under 25 Lines of Code.
Понятие логистической регрессии
Логистическая регрессияએ — это фундаментальный метод классификации. Он принадлежит к группе линейных классификаторов и чем-то похож на полиномиальную и линейную регрессию. Логистическая регрессия выполняется быстро и относительно несложно, и вам удобно интерпретировать результаты. Хотя по сути это метод двоичной классификации, его также можно применить к мультиклассовым задачам.
Предварительные требования к математике
Вам потребуется понимание сигмоидаએ и функции натурального логарифма, чтобы понять, что такое логистическая регрессия и как она работает.
Это изображение показывает сигмоиду (или S-образную кривую) некоторой переменной ?:

Сигмоида имеет значения, очень близкие к 0 или 1 в большей части своей области. Это делает его пригодным для использования в методах классификации.
На этом изображении показан натуральный логарифм \log(x) некоторой переменной x для значений x от 0 до 1:

Когда x приближается к нулю, натуральный логарифм падает до отрицательной бесконечности. Когда x = 1, \log(?) равен 0. Обратное верно для \log(1-x).
Обратите внимание, что вы часто найдете натуральный логарифм, обозначаемый \ln вместо \log. В Python math.log(x) и numpy.log(x)представляют собой натуральный логарифм x, поэтому вы будете следовать этим обозначениям в этом руководстве.
Формулировка проблемы
В этом руководстве вы увидите объяснение распространенного случая логистической регрессии, применяемой к двоичной классификации. Когда вы реализуете логистическую регрессию некоторой зависимой переменной y на множестве независимых переменных x = (x_1,\dots, x_r), где r — количество предикторов (или входных данных), вы начинаете с известных значений предикторов x_i и соответствующего фактического отклика (или результата) y_i для каждого наблюдения i = 1, \dots, n.
Ваша цель — найти функцию логистической регрессии p(?) такую, чтобы прогнозируемые ответы p(x_i) были как можно ближе к фактическому ответу y_i для каждого наблюдения i = 1,\dots, ?. Помните, что фактический ответ может быть только 0 или 1 в задачах двоичной классификации! Это означает, что каждый p(x_i) должен быть близок к 0 или 1. Вот почему удобно использовать сигмоиду.
Если у вас есть функция логистической регрессии p(x), вы можете использовать ее для прогнозирования выходных данных для новых и невидимых входов, при условии, что лежащая в основе математическая зависимость не изменилась.
Методология
Логистическая регрессия — это линейный классификатор, поэтому вы будете использовать линейную функцию f(x) = b_0 + b_1x_1 + \dots + b_rx_r, также называемую logitએ. Переменные b_0, b_1,\dots, b_r являются оценками коэффициентов регрессии, которые также называются прогнозируемыми весами или просто коэффициентами.
Функция логистической регрессии p(x) является сигмоидой f(x):
p(x) = \dfrac{1}{(1 + \exp(−? (?))}.
Таким образом, она часто близка к 0 или 1. функция p(x) часто интерпретируется как прогнозируемая вероятность того, что выход для данного равен 1. Следовательно, 1 — p(x) — это вероятность того, что выход равен 0.
Логистическая регрессия определяет наилучшие предсказанные веса b_0, b_1,\dots, b_r так, чтобы функция p(x) была как можно ближе ко всем фактическим ответам y_i, i = 1,\dots, ?, где n — количество наблюдений. Процесс вычисления лучших весов с использованием имеющихся наблюдений называется обучением модели или подгонкой.
Чтобы получить лучший вес, вы обычно максимизируете функцию логарифма правдоподобия (LLF) для всех наблюдений i = 1,\dots, ?. Этот метод называется оценкой максимального правдоподобия и представляется уравнением
LLF = \sum_i{(y_i \log(p(x_i)) + (1 — y_i) \log(1 — p(x_i)))}.
Когда y_i = 0, LLF для соответствующего наблюдения равен \log(1 — p(x_i)).
Если p(x_i) близко к y_i = 0, то \log(1 — p(x_i)) близко к 0. Это именно тот результат, который вам нужен. Если p(x_i) далеко от 0, то \log(1 — p(x_i)) значительно падает. Вы не хотите такого результата, потому что ваша цель — получить максимальный LLF. Аналогично, когда y_i = 1, LLF для этого наблюдения равен \log(p(x_i)). Если p(x_i) близко к y_i = 1, тогда \log(p(x_i)) близко к 0. Если p(x_i) далеко от 1, то \log(x_i)) — большое отрицательное число.
Существует несколько математических подходов, которые позволяют вычислить наилучшие веса, соответствующие максимальному LLF, но это выходит за рамки данного руководства. Теперь, вы можете оставить эти детали для библиотек Python логистической регрессии, которые вы научитесь использовать здесь!
После определения наилучших весов, которые определяют функцию p(x), вы можете получить прогнозируемые выходные данные p(x_i) для любого заданного входа x_i. Для каждого наблюдения i = 1,\dots, n прогнозируемый результат равен 1, если p(x_i) > 0,5 и 0 в противном случае.
Порог не обязательно должен быть 0,5, но обычно это так. Вы можете определить более низкое или более высокое значение, если это более удобно для вашей ситуации.
Есть еще одно важное соотношение между p(x) и f(x_i):
\log(\dfrac{p(?)}{(1- p(?))}) = f(?).
Это равенство объясняет, почему f(?) является logit. Отсюда следует, что p(x) = 0.5, когда f(x) = 0 и что прогнозируемый выход равен 1, если f(?) > 0 и 0 в противном случае.
Эффективность классификации
Бинарная классификация имеет четыре возможных типа результатов:
- Истинно отрицательные: правильно предсказанные негативы (нули);
- Истинно положительные: правильно предсказанные положительные (единицы);
- Ложно отрицательные: неверно предсказанные отрицания (нули);
- Ложно положительные: неверно предсказанные срабатывания (единицы).
Вы обычно оцениваете точность своего классификатора, сравнивая фактические и прогнозируемые результаты и подсчитывая правильные и неправильные прогнозы.
Самый простой индикатор точности классификации — это отношение количества правильных предсказаний к общему количеству предсказаний (или наблюдений). Другие индикаторы бинарных классификаторов включают следующее:
- Прогнозирующая ценность положительного результата — это отношение количества истинных положительных результатов к сумме количества истинных и ложных положительных результатов.
- Прогнозирующая ценность отрицательного результата — это отношение количества истинно отрицательных результатов к сумме количества истинных и ложных отрицаний.
- Чувствительность (также известная как отзыв или истинно положительный результат) — это отношение количества истинных положительных результатов к количеству фактических положительных результатов.
- Специфичность (или истинно отрицательный показатель) — это отношение количества истинных негативов к количеству реальных негативов.
- Logit f(x_1, x_2) = b_0 + b_1x_1 + b_2x_2
- Вероятности p(x_1, x_2) = \dfrac{1}{(1 + \exp(−f(x_1, x_2)))}
- Регуляризация L1 штрафует LLF масштабированной суммой абсолютных значений весов: | ?₀ | + | ?₁ | + \dots + | ?ᵣ |.
- Регуляризация L2 штрафует LLF масштабированной суммой квадратов весов: b_0^2 + b_1^2 + \dots + b_r^2.
- Регуляризация упругой сети представляет собой линейную комбинацию регуляризации L1 и L2.
- Обзор пакетов Python для логистической регрессии (NumPy, scikit‑learn, StatsModels и Matplotlib).
- Два наглядных примера логистической регрессии, решенные с помощью scikit‑learn.
- Один концептуальный пример, решенный с помощью StatsModels.
- Один из реальных примеров классификации рукописных цифр.
- Предварительная обработка данных;
- Уменьшение размерности задач;
- Проверка моделей;
- Выбор наиболее подходящей модели;
- Решение проблем регрессии и классификации;
- Внедрение кластерного анализа.
- Импорт пакетов, функций и классов.
- Получение данных для работы и, при необходимости, их трансформация.
- Создание классификационной модели и её обучение (или приспособление) к существующим данным.
- Оценка своей модели, чтобы убедиться, что её точность удовлетворительна.
Наиболее подходящий индикатор зависит от интересующей проблемы. В этом руководстве вы воспользуетесь самым простым способом определения точности классификации.
Логистическая регрессия по одной переменной
Логистическая регрессия по одной переменной — это наиболее простой случай логистической регрессии. Есть только одна независимая переменная (или характеристика), которая равна X = ?. Этот рисунок иллюстрирует одномерную логистическую регрессию:

Здесь у вас есть заданный набор пар входа-выхода (или x \rightarrow y), представленный зелеными кружками. Это ваши наблюдения. Помните, что y может быть только 0 или 1. Например, крайний левый зеленый кружок имеет вход x = 0, а фактический выход y = 0. Крайнее правое наблюдение имеет x = 9 и y = 1.
Логистическая регрессия находит веса b_0 и b_1, которые соответствуют максимальному LLF. Эти веса определяют logitએ f(x) = b_0 + b_1x, которая представляет собой черную пунктирную линию. Они также определяют прогнозируемую вероятность p(x) = \dfrac{1} {(1 + \exp (−f(x)))}, показанную здесь сплошной черной линией. В этом случае порог p(x) = 0.5 и f(x) = 0 соответствует значению x немного выше 3. Это значение является пределом между входами с прогнозируемыми выходными значениями 0 и 1.
Многовариантная логистическая регрессия
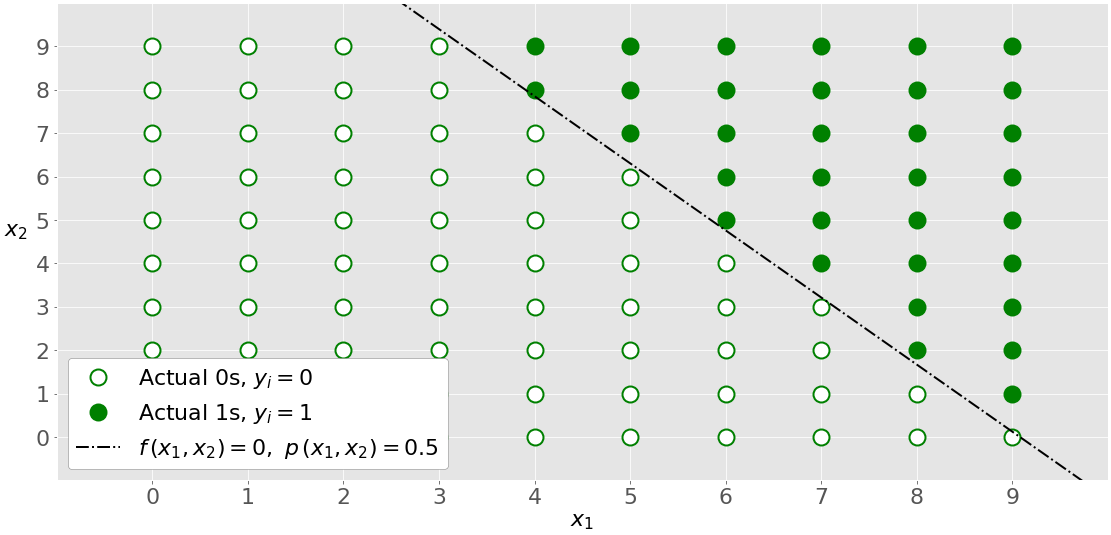
Многовариантная логистическая регрессия имеет более одной входной переменной. На этом рисунке показана классификация с двумя независимыми переменными, x_1 и x_2:

График отличается от одновариантного графика, потому что обе оси представляют входные данные. Выходы также различаются по цвету. Белые кружки показывают наблюдения, классифицированные как нули, а зеленые кружки — как единицы.
Логистическая регрессия определяет веса b_1 и b_2, которые максимизируют LLF. Когда у вас есть b_0, b_1 и b_2 можно получить:
Пунктирная черная линия линейно разделяет два класса. Эта линия соответствует p(x_1, x_2) = 0,5 и f(x_1, x_2) = 0.
Регуляризация
Переобучение — одна из самых серьезных проблем, связанных с машинным обучением. Это происходит, когда модель слишком хорошо усваивает обучающие данные. Затем модель изучает не только отношения между данными, но и шум в наборе данных. Переобученные модели, как правило, имеют хорошую точность с данными, используемыми для их соответствия (данные обучения), но они плохо себя ведут с невидимыми данными (или тестовыми данными, которые не используются для соответствия модели).
Переобучение обычно происходит со сложными моделями. Регуляризация обычно пытается уменьшить сложность модели или снизить ее. Методы регуляризации, применяемые с логистической регрессией, в основном имеют тенденцию штрафовать за большие коэффициенты b_0, b_1,\dots, b_r:
Регуляризация может значительно улучшить точность модели для невидимых данных.
Логистическая регрессия в Python
Теперь, когда вы понимаете основы, вы готовы применять соответствующие пакеты, а также их функции и классы для выполнения логистической регрессии в Python. В этом разделе вы увидите следующее:
Приступим к реализации логистической регрессии в Python!
Пакеты Python для логистической регрессии
Для логистической регрессии в Python вам понадобится несколько пакетов. Все они бесплатны, имеют открытый исходный код и множество доступных ресурсов. Во-первых, вам понадобится NumPy, фундаментальный пакет для научных и числовых вычислений на Python. NumPy полезен и популярен, потому что он позволяет выполнять высокопроизводительные операции с одно- и многомерными массивами.
В NumPy есть много полезных процедур работы с массивами. Он позволяет писать элегантный и компактный код и хорошо работает со многими пакетами Python. Если вы хотите изучить NumPy, вы можете начать с официального руководства пользователя. Справочник NumPy также предоставляет исчерпывающую документацию по его функциям, классам и методам.
Примечание. Чтобы узнать больше о производительности NumPy и других преимуществах, которые он может предложить, ознакомьтесь с Сравнение производительности Pure Python vs NumPy vs TensorFlow и Look Ma, No For-Loops: Array Programming With NumPy.
Еще один пакет Python, который вы будете использовать, — это scikit‑learn. Это одна из самых популярных библиотек для науки о данных и машинного обучения. Вы можете использовать scikit‑learn для выполнения различных функций:
Вы найдете полезную информацию на официальном сайте scikit‑learn, где вы, возможно, захотите прочитать об обобщенных линейных моделях и реализации логистической регрессии. Если вам нужна функциональность, которую scikit‑learn не может предложить, вам может пригодиться StatsModels. Это мощная библиотека Python для статистического анализа. Более подробную информацию вы можете найти на официальном сайте.
Наконец, вы будете использовать Matplotlib для визуализации результатов вашей классификации. Это всеобъемлющая библиотека Python, которая широко используется для высококачественного построения графиков.
Для получения дополнительной информации вы можете проверить официальный сайт и руководство. пользователя. Существует несколько ресурсов для изучения Matplotlib, которые могут оказаться полезными, например, Matplotlib: краткое руководство.
Логистическая регрессия в Python с помощью scikit‑learn: пример 1
Первый пример связан с проблемой двоичной классификации по одной переменной. Это наиболее простой вид классификационной задачи. При подготовке моделей классификации вы должны предпринять несколько общих шагов:
Достаточно хорошая модель, которую вы определяете, может использоваться для дальнейших прогнозов, связанных с новыми, невидимыми данными. Вышеупомянутая процедура одинакова для классификации и регрессии.
Шаг 1. Импортируйте пакеты, функции и классы
Во-первых, вам нужно импортировать Matplotlib для визуализации и NumPy для операций с массивами. Вам также понадобятся LogisticRegression, classification_report() и confusion_matrix() из scikit‑learn:
import matplotlib.pyplot as plt import numpy as np from sklearn.linear_model import LogisticRegression from sklearn.metrics import classification_report, confusion_matrix
Теперь вы импортировали все необходимое для логистической регрессии в Python с помощью scikit‑learn!
Шаг 2. Получение данных
На практике у вас обычно есть какие-то данные для работы. Для целей этого примера давайте просто создадим массивы для входных (x) и выходных (y) значений:
x = np.arange(10).reshape(-1, 1) y = np.array([0, 0, 0, 0, 1, 1, 1, 1, 1, 1])
Входные и выходные данные должны быть массивами NumPy (экземпляры класса numpy.ndarray) или аналогичными объектами. numpy.arange() создает массив последовательных, равномерно распределенных значений в заданном диапазоне. Для получения дополнительной информации об этой функции посмотрите NumPy: Справочное руководтсво.
Массив x должен быть двумерным. В нем должен быть один столбец для каждого входа, а количество строк должно быть равно количеству наблюдений. Чтобы сделать x двумерным, вы применяете .reshape() с аргументами -1, чтобы получить столько строк, сколько необходимо, и 1, чтобы получить один столбец. Для получения дополнительной информации о .reshape() вы можете ознакомиться с официальной документацией.
Вот как теперь выглядят x и y:
>>> x
array([ [0],
[1],
[2],
[3],
[4],
[5],
[6],
[7],
[8],
[9] ])
>>> y
array([0, 0, 0, 0, 1, 1, 1, 1, 1, 1])
x имеет два измерения:
- Один столбец для одного входа.
- Десять строк, каждая из которых соответствует одному наблюдению.
y — одномерный с десятью элементами. Опять же, каждый пункт соответствует одному наблюдению. Он содержит только нули и единицы, так как это проблема двоичной классификации.
Шаг 3. Создание модели и её обучение
После того, как вы подготовили вход и выход, вы можете создать и определить свою модель классификации. Вы собираетесь представить его с помощью экземпляра класса LogisticRegression:
model = LogisticRegression(solver='liblinear', random_state=0)
Приведенный выше оператор создает экземпляр LogisticRegression и связывает его ссылки с моделью переменных. LogisticRegression имеет несколько дополнительных параметров, которые определяют поведение модели и подход:
- penalty — строка (по умолчанию ‘l2‘), которая определяет, есть ли регуляризация и какой подход использовать. Другие варианты: l1, elasticnet и None.
- dual — логическое значение (по умолчанию False), которое определяет, следует ли использовать первичную (если False) или двойную формулировку (если True).
- tol — число с плавающей запятой (по умолчанию 0,0001), которое определяет допуск для остановки процедуры.
- C — положительное число с плавающей запятой (1.0 по умолчанию), которое определяет относительную силу регуляризации. Меньшие значения указывают на более сильную регуляризацию.<.li>
- fit_intercept — логическое значение (по умолчанию True), которое решает, следует ли вычислять точку пересечения b_0 (когда True) или считать ее равной нулю (когда False).
- intercept_scaling — число с плавающей запятой (1.0 по умолчанию), который определяет масштаб точки пересечения b_0.
- class_weight — словарь,
balancedилиNone(по умолчанию), который определяет веса, относящиеся к каждому классу. Когда нет, все классы имеют единицу веса. - random_state — целое число, экземпляр
numpy.RandomStateилиNone(по умолчанию), который определяет, какой генератор псевдослучайных чисел использовать. - solver — строка (по умолчанию
liblinear), которая решает, какой решатель использовать для подбора модели. Есть варианты:newton-cg,lbfgs,sagиsaga.<.li> - max_iter — целое число (по умолчанию 100), определяющее максимальное количество итераций решающей программы во время подгонки модели.<.li>
- multi_class — строка (по умолчанию
ovr), которая определяет подход к использованию нескольких классов. Другие варианты —multinomialиauto.<.li> - verbose — неотрицательное целое число (по умолчанию 0), определяющее степень детализации для решателей
liblinearиlbfgs. - warm_start — логическое значение (по умолчанию
False), которое определяет, следует ли повторно использовать ранее полученное решение. - n_jobs — целое число или
None(по умолчанию), определяющее количество используемых параллельных процессов.Noneобычно означает использование одного ядра, а -1 означает использование всех доступных ядер. - l1_ratio — это либо плавающее число точек от нуля до единицы, либо
None(по умолчанию). Оно определяет относительную важность части L1 в регуляризации elastic-net.Вам следует тщательно согласовать решатель и метод регуляризации по нескольким причинам:
- решатель ‘liblinear’ не работает без регуляризации.
- ‘newton-cg’, ‘sag’, ‘saga’ и ‘lbfgs’ не поддерживает регуляризацию L1.
- ‘saga’ — единственный решатель, который поддерживает регуляризацию elastic-net.
После того, как модель создана, ее нужно подогнать (или обучить). Подгонка модели — это процесс определения коэффициентов b_0, b_1,\dots, b_r, которые соответствуют наилучшему значению функции стоимости. Вы подходите к модели с помощью
.fit():model.fit(x, y)
.fit()принимает значения x, y и, возможно, связанные с наблюдением. Она соответствует модели и сама возвращает экземпляр модели:LogisticRegression( C=1.0, class_weight=None, dual=False, fit_intercept=True, intercept_scaling=1, l1_ratio=None, max_iter=100, multi_class='warn', n_jobs=None, penalty='l2', random_state=0, solver='liblinear', tol=0.0001, verbose=0, warm_start=False )Здесь представлено текстовое описание подобранной модели.
Вы можете использовать тот факт, что
.fit()возвращает экземпляр модели и связывает последние два оператора. Они эквивалентны следующей строке кода:model = LogisticRegression(solver='liblinear', random_state=0).fit(x, y)
На этом этапе у вас определена модель классификации.
Вы можете быстро получить атрибуты своей модели. Например, атрибут
.classes_представляет собой массив различных значений, которые принимаетy:>>> model.classes_ array([0, 1])
Это пример двоичной классификации, и
yможет быть 0 или 1, как указано выше.Вы также можете получить значение наклона b_1 и точку пересечения b_0 линейной функции f следующим образом:
>>> model.intercept_ array([-1.04608067]) >>> model.coef_ array([ [0.51491375] ])
Как видите, b_0 задается внутри одномерного массива, а b_1 — внутри двумерного массива. Вы используете атрибуты
.intercept_и.coef_, чтобы получить эти результаты.Шаг 4: Оценка модели
Как только модель определена, вы можете проверить ее точность с помощью
.predict_proba(), который возвращает матрицу вероятностей того, что прогнозируемый результат равен нулю или единице:>>> model.predict_proba(x) array([ [0.74002157, 0.25997843], [0.62975524, 0.37024476], [0.5040632 , 0.4959368 ], [0.37785549, 0.62214451], [0.26628093, 0.73371907], [0.17821501, 0.82178499], [0.11472079, 0.88527921], [0.07186982, 0.92813018], [0.04422513, 0.95577487], [0.02690569, 0.97309431] ])В приведенной выше матрице каждая строка соответствует одному наблюдению. Первый столбец — это вероятность того, что прогнозируемый результат будет равен нулю, то есть 1 - p(x). Второй столбец — это вероятность того, что на выходе будет единица или p(x).
Вы можете получить фактические прогнозы на основе матрицы вероятностей и значений p(x) с помощью
.predict():>>> model.predict(x) array([0, 0, 0, 1, 1, 1, 1, 1, 1, 1])
Эта функция возвращает предсказанные выходные значения в виде одномерного массива.
На рисунке ниже показаны результаты входа, выхода и классификации:
Зеленые круги представляют фактические ответы, а также правильные прогнозы. Красный \times показывает неверный прогноз. Сплошная черная линия — это предполагаемая линия логистической регрессии p(x). Серые квадраты — это точки на этой линии, которые соответствуют x и значениям во втором столбце матрицы вероятностей. Черная пунктирная линия — logit f(x).
Значение × немного выше 2 соответствует порогу p(x) = 0,5, что составляет f(x) = 0. Это значение \times является границей между точками, которые классифицируются как нули, и точками, предсказанными как единицы.
Например, первая точка имеет вход input = 0, фактический выход ouput = 0, вероятность p = 0,26 и прогнозируемое значение 0. Вторая точка имеет x = 1, y = 0, p = 0,37 и прогноз 0. Только четвертая точка имеет фактический результат y = 0 и вероятность выше 0,5 (при p = 0,62), поэтому он ошибочно классифицируется как 1. Все остальные значения предсказываются правильно.
Если девять из десяти наблюдений классифицированы правильно, точность вашей модели равна 9/10 = 0,9, которую вы можете получить с помощью
.score():>>> model.score(x, y) 0.9
.score()принимает входные и выходные данные в качестве аргументов и возвращает отношение количества правильных прогнозов к количеству наблюдений.Вы можете получить больше информации о точности модели с помощью матрицы ошибок. В случае бинарной классификации матрица ошибок показывает следующие числа:
- Истинные минусы в верхнем левом углу.
- Ложные минусы в нижнем левом углу.
- Ложные плюсы в правом верхнем углу.
- Истинные плюсы в правом нижнем углу.
Чтобы создать матрицу ошибок, вы можете использовать
confusion_matrix()и предоставить фактические и прогнозируемые результаты в качестве аргументов:>>> confusion_matrix(y, model.predict(x)) array([ [3, 1], [0, 6] ])Полученная матрица показывает следующее:
- Три истинно отрицательных прогноза: первые три наблюдения — это правильно предсказанные нули.
- Никаких ложноотрицательных прогнозов: это те, которые ошибочно предсказаны как нули.
- Одно ложноположительное предсказание: четвертое наблюдение — это ноль, который был ошибочно предсказан как единица.
- Шесть истинно положительных предсказаний: последние шесть наблюдений предсказаны правильно.
Часто бывает полезно визуализировать матрицу ошибок. Вы можете сделать это с помощью
.imshow()из Matplotlib, который принимает матрицу ошибок в качестве аргумента:cm = confusion_matrix(y, model.predict(x)) fig, ax = plt.subplots(figsize=(8, 8)) ax.imshow(cm) ax.grid(False) ax.xaxis.set(ticks=(0, 1), ticklabels=('Predicted 0s', 'Predicted 1s')) ax.yaxis.set(ticks=(0, 1), ticklabels=('Actual 0s', 'Actual 1s')) ax.set_ylim(1.5, -0.5) for i in range(2): for j in range(2): ax.text(j, i, cm[i, j], ha='center', va='center', color='red') plt.show()Приведенный выше код создает тепловую карту, которая и есть визуальное представление матрицы ошибок:
На этом рисунке разные цвета представляют разные числа, а похожие цвета представляют похожие числа. Тепловые карты — хороший и удобный способ представить матрицу. Чтобы узнать о них больше, ознакомьтесь с документацией Matplotlib по созданию аннотированных тепловых карт и .imshow().
Вы можете получить более полный отчет о классификации с помощью метода
classification_report():>>> print(classification_report(y, model.predict(x))) precision recall f1-score support 0 1.00 0.75 0.86 4 1 0.86 1.00 0.92 6 accuracy 0.90 10 macro avg 0.93 0.88 0.89 10 weighted avg 0.91 0.90 0.90 10Эта функция также принимает фактические и прогнозируемые выходные данные в качестве аргументов. Она возвращает отчет о классификации в виде словаря, если вы указали
output_dict = Trueили строку в противном случае.Примечание. Обычно для оценки модели лучше использовать данные, которые вы не использовали для обучения. Так вы избегаете предвзятости и обнаруживаете переобучение. Позже здесь вы увидите пример.
Для получения дополнительной информации о LogisticRegression ознакомьтесь с официальной документацией. Кроме того, scikit‑learn предлагает аналогичный класс LogisticRegressionCV и это есть перекрестная проверкаએ. Вы также можете ознакомиться с официальной документацией, чтобы узнать больше о классификационных отчетах и матрицах ошибок.
Улучшение модели
Вы можете улучшить свою модель, задав разные параметры. Например, давайте работать с силой регуляризации C, равной 10,0, вместо значения по умолчанию 1,0:
model = LogisticRegression(solver='liblinear', C=10.0, random_state=0) model.fit(x, y)
Теперь у вас есть еще одна модель с другими параметрами. Он также будет иметь другую матрицу вероятностей и другой набор коэффициентов и прогнозов:
>>> model.intercept_ array([-3.51335372]) >>> model.coef_ array([ [1.12066084] ]) >>> model.predict_proba(x) array([ [0.97106534, 0.02893466], [0.9162684 , 0.0837316 ], [0.7810904 , 0.2189096 ], [0.53777071, 0.46222929], [0.27502212, 0.72497788], [0.11007743, 0.88992257], [0.03876835, 0.96123165], [0.01298011, 0.98701989], [0.0042697 , 0.9957303 ], [0.00139621, 0.99860379] ]) >>> model.predict(x) array([0, 0, 0, 0, 1, 1, 1, 1, 1, 1])Как видите, абсолютные значения точки пересечения b_0 и коэффициента b_1 и больше. Это так, потому что большее значение C означает более слабую регуляризацию или более слабые штрафы, связанные с высокими значениями b_0 и b_1.
Различные значения b_0 и b_1 предполагают изменение logitа f(x), разные значения вероятностей p(x), другая форма линии регрессии и, возможно, изменения в других прогнозируемых выходных данных и производительности классификации. Граничное значение x, для которого p(x) = 0,5 и f(x) = 0, теперь выше. Оно выше 3. В этом случае вы получаете все истинные прогнозы, о чем свидетельствуют точность, матрица ошибок и отчет о классификации:
>>> model.score(x, y) 1.0 >>> confusion_matrix(y, model.predict(x)) array([ [4, 0], [0, 6] ]) >>> print(classification_report(y, model.predict(x))) precision recall f1-score support 0 1.00 1.00 1.00 4 1 1.00 1.00 1.00 6 accuracy 1.00 10 macro avg 1.00 1.00 1.00 10 weighted avg 1.00 1.00 1.00 10Оценка (или точность) 1 и нули в нижнем левом и верхнем правом полях матрицы ошибок указывают на то, что фактический и прогнозируемый выходные данные совпадают. Это также показано на рисунке ниже:
На этом рисунке показано, что оценочная линия регрессии теперь имеет другую форму и что четвертая точка правильно классифицируется как 0. Красный знак \times отсутствует, поэтому нет неверного прогноза.
Логистическая регрессия в Python с помощью scikit‑learn: пример 2
Решим еще одну задачу классификации. Она похожа на предыдущую, только за исключением того, что выход отличается вторым значением. Код будет аналогичен предыдущему случаю:
# Шаг 1. Импортируйте пакеты, функции и классы import numpy as np from sklearn.linear_model import LogisticRegression from sklearn.metrics import classification_report, confusion_matrix # Шаг 2. Получите данные x = np.arange(10).reshape(-1, 1) y = np.array([0, 1, 0, 0, 1, 1, 1, 1, 1, 1]) # Шаг 3. Создайте модель и обучите ее model = LogisticRegression(solver='liblinear', C=10.0, random_state=0) model.fit(x, y) # Шаг 4. Оцените модель p_pred = model.predict_proba(x) y_pred = model.predict(x) score_ = model.score(x, y) conf_m = confusion_matrix(y, y_pred) report = classification_report(y, y_pred)
Этот образец кода классификации дает следующие результаты:
>>> print('x:', x, sep='\n') x: [ [0] [1] [2] [3] [4] [5] [6] [7] [8] [9] ] >>> print('y:', y, sep='\n', end='\n\n') y: [0 1 0 0 1 1 1 1 1 1] >>> print('intercept:', model.intercept_) intercept: [-1.51632619] >>> print('coef:', model.coef_, end='\n\n') coef: [ [0.703457] ] >>> print('p_pred:', p_pred, sep='\n', end='\n\n') p_pred: [ [0.81999686 0.18000314] [0.69272057 0.30727943] [0.52732579 0.47267421] [0.35570732 0.64429268] [0.21458576 0.78541424] [0.11910229 0.88089771] [0.06271329 0.93728671] [0.03205032 0.96794968] [0.0161218 0.9838782 ] [0.00804372 0.99195628] ] >>> print('y_pred:', y_pred, end='\n\n') y_pred: [0 0 0 1 1 1 1 1 1 1] >>> print('score_:', score_, end='\n\n') score_: 0.8 >>> print('conf_m:', conf_m, sep='\n', end='\n\n') conf_m: [ [2 1] [1 6] ] >>> print('report:', report, sep='\n') report: precision recall f1-score support 0 0.67 0.67 0.67 3 1 0.86 0.86 0.86 7 accuracy 0.80 10 macro avg 0.76 0.76 0.76 10 weighted avg 0.80 0.80 0.80 10В этом случае оценка (или точность) составляет 0,8. Есть два наблюдения, классифицированных неправильно. Один из них — ложноотрицательный, другой — ложноположительный.
На рисунке ниже показан этот пример с восемью правильными и двумя неправильными прогнозами:
Этот рисунок раскрывает одну важную характеристику этого примера. В отличие от предыдущей, эта задача линейно не разделима. Это означает, что вы не можете найти значение и провести прямую линию, чтобы разделить наблюдения с = 0 и наблюдения с = 1. Такой строчки нет.
Имейте в виду, что логистическая регрессия — это, по сути, линейный классификатор, поэтому вы теоретически не можете создать модель логистической регрессии с точностью до 1 в этом случае.
Логистическая регрессия в Python с помощью StatsModels: пример
Вы также можете реализовать логистическую регрессию в Python с помощью пакета StatsModels. Обычно это требуется, когда вам нужно больше статистических данных, относящихся к моделям и результатам. Процедура аналогична scikit‑learn.
Шаг 1. Импортируйте пакеты
Все, что вам нужно для импорта, это NumPy и
statsmodels.api:import numpy as np import statsmodels.api as sm
Теперь у вас есть нужные пакеты.
Шаг 2. Получите данные
Вы можете получать входные и выходные данные так же, как и в scikit‑learn. Однако, StatsModels не принимает во внимание перехват b_0 и вам необходимо включить дополнительный столбец единиц в x. Вы делаете это с помощью
add_constant():x = np.arange(10).reshape(-1, 1) y = np.array([0, 1, 0, 0, 1, 1, 1, 1, 1, 1]) x = sm.add_constant(x)
add_constant()принимает массив x в качестве аргумента и возвращает новый массив с дополнительным столбцом единиц. Вот как выглядятxиy:>>> x array([ [1., 0.], [1., 1.], [1., 2.], [1., 3.], [1., 4.], [1., 5.], [1., 6.], [1., 7.], [1., 8.], [1., 9.] ]) >>> y array([0, 1, 0, 0, 1, 1, 1, 1, 1, 1])Это ваши данные. Первый столбец
xсоответствует точке пересечения b_0. Второй столбец содержит исходные значения x.Шаг 3. Создайте модель и обучите её
Ваша модель логистической регрессии будет экземпляром класса
statsmodels.discrete.discrete_model.Logit. Вот как вы можете его создать:>>> model = sm.Logit(y, x)
Обратите внимание, что первым аргументом здесь является
y, за которым следуетx.Теперь вы создали свою модель и должны подогнать ее к существующим данным. Вы делаете это с помощью
.fit()или, если хотите применить регуляризацию L1, с помощью.fit_regularized():>>> result = model.fit(method='newton') Optimization terminated successfully. Current function value: 0.350471 Iterations 7Теперь модель готова, и переменный результат содержит полезные данные. Например, вы можете получить значения b_0 и b_1 с помощью
.params:>>> result.params array([-1.972805 , 0.82240094])
Первый элемент полученного массива — это точка пересечения b_0, а второй — наклон b_1. Для получения дополнительной информации вы можете посмотреть официальную документацию по Logit, а также по .fit() и .fit_regularized().
Шаг 4: Оцените модель
Вы можете использовать результаты, чтобы получить вероятность того, что прогнозируемые результаты будут равны единице:
>>> result.predict(x) array([0.12208792, 0.24041529, 0.41872657, 0.62114189, 0.78864861, 0.89465521, 0.95080891, 0.97777369, 0.99011108, 0.99563083])Эти вероятности рассчитываются с помощью
.predict(). Вы можете использовать их значения для получения фактических прогнозируемых результатов:>>> (result.predict(x) >= 0.5).astype(int) array([0, 0, 0, 1, 1, 1, 1, 1, 1, 1])
Полученный массив содержит прогнозируемые выходные значения. Как видите, b_0, b_1 и вероятности, полученные с помощью scikit‑learn и StatsModels, различны. Это следствие применения различных итерационных и приближенных процедур и параметров. Однако в этом случае вы получите те же прогнозируемые результаты, что и при использовании scikit‑learn.
Вы можете получить матрицу ошибок с помощью
.pred_table():>>> result.pred_table() array([ [2., 1.], [1., 6.] ])Этот пример такой же, как и при использовании scikit‑learn, потому что прогнозируемые результаты равны. Матрицы ошибок, полученные с помощью StatsModels и scikit‑learn, различаются типами их элементов (числа с плавающей запятой и целые числа).
.summary()и.summary2()получают выходные данные, которые могут оказаться полезными в некоторых случаях:>>> result.summary()
""" Logit Regression Results ============================================================================== Dep. Variable: y No. Observations: 10 Model: Logit Df Residuals: 8 Method: MLE Df Model: 1 Date: Sun, 23 Jun 2019 Pseudo R-squ.: 0.4263 Time: 21:43:49 Log-Likelihood: -3.5047 converged: True LL-Null: -6.1086 LLR p-value: 0.02248 ============================================================================== coef std err z P>|z| [0.025 0.975] ------------------------------------------------------------------------------ const -1.9728 1.737 -1.136 0.256 -5.377 1.431 x1 0.8224 0.528 1.557 0.119 -0.213 1.858 ============================================================================== """ >>> result.summary2() """ Results: Logit =============================================================== Model: Logit Pseudo R-squared: 0.426 Dependent Variable: y AIC: 11.0094 Date: 2019-06-23 21:43 BIC: 11.6146 No. Observations: 10 Log-Likelihood: -3.5047 Df Model: 1 LL-Null: -6.1086 Df Residuals: 8 LLR p-value: 0.022485 Converged: 1.0000 Scale: 1.0000 No. Iterations: 7.0000 ----------------------------------------------------------------- Coef. Std.Err. z P>|z| [0.025 0.975] ----------------------------------------------------------------- const -1.9728 1.7366 -1.1360 0.2560 -5.3765 1.4309 x1 0.8224 0.5281 1.5572 0.1194 -0.2127 1.8575 =============================================================== """ Это подробные отчеты со значениями, которые можно получить с помощью соответствующих методов и атрибутов. Для получения дополнительной информации ознакомьтесь с официальной документацией по LogitResults.
Логистическая регрессия в Python: распознавание рукописного ввода
Предыдущие примеры иллюстрировали реализацию логистической регрессии в Python, а также некоторые детали, связанные с этим методом. В следующем примере показано, как использовать логистическую регрессию для решения реальной проблемы классификации. Подход очень похож на то, что вы уже видели, но с большим набором данных и несколькими дополнительными проблемами.
Этот пример касается распознавания изображений. Если быть более точным, вы будете работать над распознаванием рукописных цифр. Вы будете использовать набор данных с 1797 наблюдениями, каждое из которых представляет собой изображение одной рукописной цифры. Каждое изображение имеет размер 64 пикселя, ширину 8 пикселей и высоту 8 пикселей.
Примечание. Чтобы узнать больше об этом наборе данных, обратитесь к официальной документации.
inputs(x) — это векторы с 64 измерениями или значениями. Каждый входной вектор описывает одно изображение. Каждое из 64 значений представляет один пиксель изображения. Входные значения — это целые числа от 0 до 16, в зависимости от оттенка серого для соответствующего пикселя. outputs(y) каждого наблюдения является целое число от 0 до 9, соответствует цифре на изображении. Всего существует десять классов, каждый из которых соответствует одному изображению.
Шаг 1. Импортируйте пакеты
Вам нужно будет импортировать Matplotlib, NumPy, а также несколько функций и классов из scikit‑learn:
import matplotlib.pyplot as plt import numpy as np from sklearn.datasets import load_digits from sklearn.linear_model import LogisticRegression from sklearn.metrics import classification_report, confusion_matrix from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler
Это оно! У вас есть все функции, необходимые для выполнения классификации.
Шаг 2а: Получите данные
Вы можете получить набор данных прямо из scikit‑learn с помощью
load_digits(). Он возвращает кортеж входных и выходных данных:x, y = load_digits(return_X_y=True)
Теперь у вас есть данные. Вот как выглядят
xиy:>>> x array([ [ 0., 0., 5., ..., 0., 0., 0.], [ 0., 0., 0., ..., 10., 0., 0.], [ 0., 0., 0., ..., 16., 9., 0.], ..., [ 0., 0., 1., ..., 6., 0., 0.], [ 0., 0., 2., ..., 12., 0., 0.], [ 0., 0., 10., ..., 12., 1., 0.] ]) >>> y array([0, 1, 2, ..., 8, 9, 8])Это ваши данные, с которыми нужно работать.
x— это многомерный массив с 1797 строками и 64 столбцами. Он содержит целые числа от 0 до 16.y— одномерный массив с 1797 целыми числами от 0 до 9.Шаг 2b: разделение данных
Хорошая и широко распространенная практика — разделить набор данных, с которым вы работаете, на два подмножества. Это обучающий набор и тестовый набор. Это разделение обычно выполняется случайным образом. Вы должны использовать обучающий набор в соответствии с вашей моделью. После того, как модель найдена, вы оцениваете ее характеристики с помощью набора для испытаний. Важно не использовать тестовый набор в процессе обучения модели. Такой подход позволяет объективно оценить модель. Один из способов разделить ваш набор данных на обучающий и тестовый — применить train_test_split():
x_train, x_test, y_train, y_test =\ train_test_split(x, y, test_size=0.2, random_state=0)train_test_split() принимает
xиy. Он также принимаетtest_size, который определяет размер набора тестов, иrandom_state, чтобы определить состояние генератора псевдослучайных чисел, а также другие необязательные аргументы. Эта функция возвращает список с четырьмя массивами:- x_train: часть x, используемая для соответствия модели;
- x_test: часть x, используемая для оценки модели;
- y_train: часть y, соответствующая x_train;
- y_test: часть y, которая соответствует x_test.
После разделения данных вы можете забыть о
x_testиy_test, пока не определите свою модель.Шаг 2c: масштабирование данных
Стандартизация — это процесс преобразования данных таким образом, что среднее значение каждого столбца становится равным нулю, а стандартное отклонение каждого столбца равно единице. Таким образом, вы получите одинаковый масштаб для всех столбцов. Сделайте следующие шаги для стандартизации ваших данных:
- Рассчитайте среднее значение и стандартное отклонение для каждого столбца.
- Вычтите соответствующее среднее значение из каждого элемента.
- Разделите полученную разницу на соответствующее стандартное отклонение.
Рекомендуется стандартизировать входные данные, которые вы используете для логистической регрессии, хотя во многих случаях в этом нет необходимости. Стандартизация может улучшить производительность вашего алгоритма. Это помогает, если вам нужно сравнить и интерпретировать веса. Это важно, когда вы применяете штрафы, потому что алгоритм на самом деле штрафует за большие значения весов.
Вы можете стандартизировать свои входные данные, создав экземпляр
StandardScalerи вызвав для него.fit_transform():scaler = StandardScaler() x_train = scaler.fit_transform(x_train)
.fit_transform()помещает экземплярStandardScalerв массив, переданный в качестве аргумента, преобразует этот массив и возвращает новый стандартизованный массив. Теперьx_train— это стандартизированный входной массив.Шаг 3. Создайте модель и обучите её
Этот шаг очень похож на предыдущие примеры. Единственная разница в том, что вы используете подмножества
x_trainиy_trainдля соответствия модели. Опять же, вы должны создать экземплярLogisticRegressionи вызвать для него.fit():model = LogisticRegression(solver='liblinear', C=0.05, multi_class='ovr', random_state=0) model.fit(x_train, y_train)Когда вы работаете с проблемами с более чем двумя классами, вы должны указать параметр multi_class в LogisticRegression. Он определяет, как решить проблему:
- ‘ovr‘ говорит, что двоичный файл подходит для каждого класса.
- ‘multinomial‘ означает применение полиномиальной подгонки потерь.
Последний оператор дает следующий результат, поскольку
.fit()возвращает саму модель:LogisticRegression( C=0.05, class_weight=None, dual=False, fit_intercept=True, intercept_scaling=1, l1_ratio=None, max_iter=100, multi_class='ovr', n_jobs=None, penalty='l2', random_state=0, solver='liblinear', tol=0.0001, verbose=0, warm_start=False)Это параметры вашей модели. Теперь она определена и готов к следующему шагу.
Шаг 4: Оцените модель
Вы должны оценить свою модель аналогично тому, что вы делали в предыдущих примерах, с той разницей, что вы в основном будете использовать x_test и y_test, которые не используются для обучения. Если вы решили стандартизировать x_train, то полученная модель полагается на масштабированные данные, поэтому x_test также следует масштабировать с помощью того же экземпляра
StandardScaler:x_test = scaler.transform(x_test)
Вот как вы получаете новый, правильно масштабированный x_test. В этом случае вы используете
.transform(), который только преобразует аргумент, без установки масштаба.Вы можете получить прогнозируемые результаты с помощью
.predict():y_pred = model.predict(x_test)
Переменная
y_predтеперь привязана к массиву предсказанных выходных данных. Обратите внимание, что здесь в качестве аргумента используетсяx_test.Вы можете получить точность с помощью
.score():>>> model.score(x_train, y_train) 0.964509394572025 >>> model.score(x_test, y_test) 0.9416666666666667
Фактически, вы можете получить два значения точности: одно получено с помощью обучающего набора, а другое — с помощью набора тестов. Было бы неплохо сравнить эти два, поскольку ситуация, когда точность обучающего набора намного выше, может указывать на переобучение. Точность набора тестов более важна для оценки валидности на невидимых данных, поскольку она не является предвзятой.
Вы можете получить матрицу ошибок с
confusion_matrix():>>> confusion_matrix(y_test, y_pred) array([ [27, 0, 0, 0, 0, 0, 0, 0, 0, 0], [ 0, 32, 0, 0, 0, 0, 1, 0, 1, 1], [ 1, 1, 33, 1, 0, 0, 0, 0, 0, 0], [ 0, 0, 1, 28, 0, 0, 0, 0, 0, 0], [ 0, 0, 0, 0, 29, 0, 0, 1, 0, 0], [ 0, 0, 0, 0, 0, 39, 0, 0, 0, 1], [ 0, 1, 0, 0, 0, 0, 43, 0, 0, 0], [ 0, 0, 0, 0, 0, 0, 0, 39, 0, 0], [ 0, 2, 1, 2, 0, 0, 0, 1, 33, 0], [ 0, 0, 0, 1, 0, 1, 0, 2, 1, 36] ])Полученная матрица ошибок имеет большие размеры. В данном случае у него 100 номеров. Это ситуация, когда было бы действительно полезно визуализировать её:
cm = confusion_matrix(y_test, y_pred) fig, ax = plt.subplots(figsize=(8, 8)) ax.imshow(cm) ax.grid(False) ax.set_xlabel('Predicted outputs', fontsize=font_size, color='black') ax.set_ylabel('Actual outputs', fontsize=font_size, color='black') ax.xaxis.set(ticks=range(10)) ax.yaxis.set(ticks=range(10)) ax.set_ylim(9.5, -0.5) for i in range(10): for j in range(10): ax.text(j, i, cm[i, j], ha='center', va='center', color='white') plt.show()Вот вам визуальное представление матрицы ошибок, полученное этим кодом:
Это тепловая карта, которая иллюстрирует матрицу ошибок с числами и цветами. Вы можете видеть, что оттенки фиолетового представляют небольшие числа (например, 0, 1 или 2), в то время как зеленый и желтый показывают гораздо большие числа (27 и выше).
Цифры на главной диагонали (27, 32,…, 36) показывают количество правильных прогнозов из тестового набора. Например, есть 27 изображений с нулем, 32 изображения с одним и так далее, которые правильно классифицированы. Остальные числа соответствуют неверным предсказаниям. Например, цифра 1 в третьей строке и первом столбце показывает, что есть одно изображение с номером 2, ошибочно классифицированным как 0.
В заключение,вы можете получить отчет о классификации в виде строки или словаря с помощью метода
classification_report():>>> print(classification_report(y_test, y_pred)) precision recall f1-score support 0 0.96 1.00 0.98 27 1 0.89 0.91 0.90 35 2 0.94 0.92 0.93 36 3 0.88 0.97 0.92 29 4 1.00 0.97 0.98 30 5 0.97 0.97 0.97 40 6 0.98 0.98 0.98 44 7 0.91 1.00 0.95 39 8 0.94 0.85 0.89 39 9 0.95 0.88 0.91 41 accuracy 0.94 360 macro avg 0.94 0.94 0.94 360 weighted avg 0.94 0.94 0.94 360В этом отчете представлена дополнительная информация, например, поддержка и точность классификации каждой цифры.
За пределами логистической регрессии в Python
Логистическая регрессия — это фундаментальный метод классификации. Это относительно несложный линейный классификатор. Несмотря на свою простоту и популярность, бывают случаи (особенно с очень сложными моделями), когда логистическая регрессия не работает. В таких обстоятельствах вы можете использовать другие методы классификации:
- k-Ближайшие соседи;
- Наивные байесовские классификаторы;
- Машины опорных векторов;
- Деревья решений;
- Случайные леса;
- Нейронные сети;
К счастью, существует несколько всеобъемлющих библиотек Python для машинного обучения, которые реализуют эти методы. Например, пакет scikit‑learn, который вы видели здесь в действии, реализует все вышеупомянутые методы,за исключением нейронных сетей.
Для всех этих методов scikit‑learn предлагает подходящие классы с такими методами, как model.fit(), model.predict_proba(), model.predict(), model.score() и так далее. Вы можете комбинировать их с train_test_split(), confusion_matrix(), classification_report() и другими.
Нейронные сети (включая глубокие нейронные сети) стали очень популярными для задач классификации. Такие библиотеки, как TensorFlow, PyTorch или Keras предлагают подходящую, производительную и мощную поддержку для этих типов моделей.
Заключение
Теперь вы знаете, что такое логистическая регрессия и как ее можно реализовать для классификации с помощью Python. Вы использовали множество пакетов с открытым исходным кодом, включая NumPy, для работы с массивами и Matplotlib для визуализации результатов. Вы также использовали scikit‑learn и StatsModels для создания, подгонки, оценки и применения моделей.
В общем-то, логистическая регрессия в Python имеет простую и удобную реализацию. Обычно он состоит из следующих шагов:
- Импорт пакетов, функций и классов
- Получение данные для работы и, при необходимости, их трансформация
- Создание моделей классификации и обучение (или подгонку) её с существующими данными
- Оценка свою модель, чтобы убедиться, что ее точность удовлетворительна.
- Применение своей модели для прогнозирования
Вы прошли долгий путь в понимании одной из важнейших областей машинного обучения! Если у вас есть вопросы или комментарии, пожалуйста, оставьте их в разделе комментариев ниже.
По мотивам Logistic Regression in Python




